Parcae adalah arsitektur looped transformer yang stabil dan efisien, memungkinkan model AI berkualitas tinggi dengan memory footprint lebih kecil.
Selama ini, cara bikin language model yang lebih bagus cuma satu: tambah parameter, tambah data, tambah compute. Tapi semakin banyak AI yang jalan di edge device, pertanyaannya jadi: bisa nggak sih kualitas naik tanpa memory yang ikut membengkak?
Tim dari UC San Diego dan Together AI punya jawabannya. Mereka bikin Parcae, arsitektur looped yang stabil dan bisa ngalahin transformer biasa di semua skala yang diuji.
Yang menarik, Parcae pakai jumlah parameter dan data training yang sama persis.
Jadi sebenarnya apa sih looped language model ini?
Di transformer standar, data cuma lewat sekali ke tumpukan layer yang sudah fix. Looped model beda: layer yang sama dipakai berulang-ulang, jadi compute naik tapi parameter tetap.
Bayangin aja kayak ngejalanin blok transformer yang sama beberapa kali, bukan numpuk layer baru.
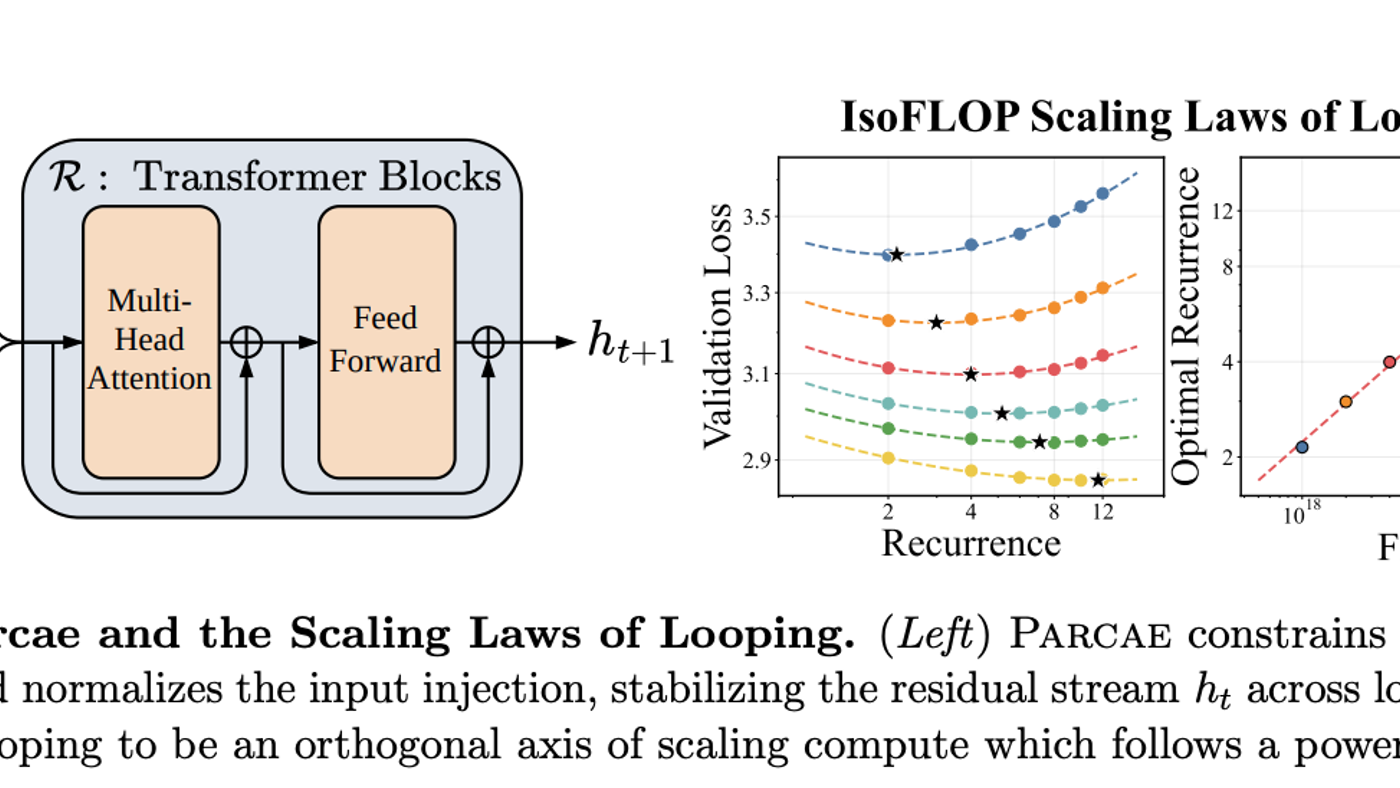
Parcae punya tiga bagian: prelude buat embed input, recurrent block yang update hidden state berkali-kali, dan coda buat hasilkan output. Desain ini bikin model tetap ringan di memory tapi tetap powerful.
Masalahnya, looped model sebelumnya susah banget ditraining.
Ada yang namanya residual state explosion, di mana hidden state makin gede nggak terkontrol tiap iterasi. Loss juga sering spike tiba-tiba. Hyperparameter harus di-tune dengan hati-hati banget baru bisa konvergen.
Tim riset Parcae nemu akar masalahnya: sistem residual yang nggak dikontrol.
Mereka nyusun ulang forward pass sebagai dynamical system. Dari sini, stabilitas bisa diukur pakai spectral norm. Kalau nilainya di atas 1, sistem unstable. Metode sebelumnya? Kebanyakan marginally stable atau bahkan unstable.
Parcae beda. Dia pakai teknik dari state space model kayak Mamba dan S4.
Dengan learned step size dan negative diagonal matrix, spectral norm selalu di bawah 1. Stabilitas terjamin by design, nggak perlu trik-trikan.
Hasilnya? Training jadi stabil di berbagai learning rate, yang sebelumnya bikin model lain divergen.
Di dataset Huginn, Parcae turunin validation perplexity sampai 6.3% dibanding RDM. WikiText perplexity naik 9.1% di skala 350M. Zero-shot benchmark naik 1.8 poin.
Yang paling keren: Parcae 770M parameter selevel dengan transformer 1.3B parameter.
Artinya, kamu bisa dapet kualitas sama dengan memory setengahnya. Tim riset bilang Parcae bisa dapet 87.5% kualitas dari transformer yang dua kali lebih gede.
Ini juga riset pertama yang bikin scaling laws buat layer looping.
Dari eksperimen isoFLOP, optimal mean recurrence naik mengikuti power law seiring compute budget. Looping itu axis ketiga buat scaling, selain parameter dan data.
Tapi ada catatan penting soal test-time looping.
Kamu bisa tambah loop iteration pas inference, tapi gain-nya bakal plateau di sekitar mean recurrence yang dipakai training. Nggak bisa infinite loop tanpa training lebih dulu di depth yang lebih dalam.
Praktisnya gini: kalau kamu develop AI untuk device dengan memory terbatas, Parcae kasih opsi baru. Daripada beli hardware lebih gahar, kamu bisa optimize arsitektur dengan looping yang terkontrol.
Yang perlu diingat: training depth itu ceiling. Mau scaling pas inference? Training-nya harus cukup dalam dulu. Ini trade-off yang harus dihitung dari awal development.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→