Xiaomi meluncurkan MiMo-V2.5-Pro dan MiMo-V2.5, dua model AI agentic open source yang mampu menandingi performa frontier model dengan biaya token 40-60% lebih rendah.
Tim MiMo dari Xiaomi baru aja merilis dua model keren: MiMo-V2.5-Pro dan MiMo-V2.5. Dari benchmark yang dirilis, open-source agentic AI sekarang makin deket banget sama level model-model besar kayak Claude dan GPT.
Kedua model ini udah bisa dipakai lewat API dan harganya kompetitif. Buat kamu yang bangun pipeline AI agent, ini bisa jadi alternatif serius yang lebih transparan dan bisa di-audit.
Nah, sebelum lanjut, apa sih sebenarnya agentic model itu? Bedanya sama LLM biasa?
Mayoritas benchmark LLM itu ngetes kemampuan model jawab satu pertanyaan. Agentic benchmark lebih keras — ngetes apakah model bisa nyelesain goal multi-step secara otonom, pakai tools kayak web search, eksekusi kode, file I/O, dan API calls selama banyak turn.
Bedanya kayak: model yang bisa jawab "gimana cara nulis lexer?" versus model yang beneran bisa nulis compiler lengkap, jalanin test, nangkep regression, dan fix sendiri — tanpa bantuan manusia.
MiMo-V2.5-Pro adalah model paling canggih Xiaomi sampai sekarang. Improvement signifikan dari MiMo-V2-Pro di agentic capabilities, software engineering kompleks, dan long-horizon tasks.
Angka benchmark-nya kompetitif banget: SWE-bench Pro 57.2, Claw-Eval 63.8, τ3-Bench 72.9 — selevel sama Claude Opus 4.6 dan GPT-5.4.
V2.5-Pro bisa sustain task kompleks yang butuh lebih dari seribu tool calls. Improvement signifikan di instruction following dan koherensi di konteks ultra-panjang.
Satu hal yang beda dari V2.5-Pro adalah "harness awareness" — model ini aktif optimize working environment-nya sendiri buat stay on track di task yang panjang.
Xiaomi rilis tiga demo real-world yang nunjukin kemampuan ini secara konkret.
Demo pertama: SysY Compiler in Rust. Task dari course Peking University yang biasanya butuh beberapa minggu buat mahasiswa CS. MiMo-V2.5-Pro nyelesain dalam 4.3 jam dengan 672 tool calls, skor sempurna 233/233.
Yang keren bukan cuma skor akhirnya, tapi arsitektur eksekusinya. Model ini bangun compiler layer by layer: scaffold pipeline dulu, perfect Koopa IR (110/110), baru RISC-V backend (103/103), terakhir performance (20/20).
Compile pertama udah lolos 137/233 test — 59% cold start yang nunjukin arsitektur udah bener dari awal. Pas refactoring bikin regression, model diagnose, recover, dan lanjut. Ini engineering behavior yang structured dan self-correcting.
Demo kedua: Full-Featured Desktop Video Editor. Cuma dari beberapa prompt sederhana, model deliver aplikasi desktop working dengan multi-track timeline, clip trimming, cross-fades, audio mixing, dan export pipeline. Total 8.192 baris kode, 1.868 tool calls, 11.5 jam kerja otonom.
Demo ketiga paling teknis: Analog EDA-FVF-LDO Design. Task level graduate buat design dan optimize FVF-LDO (Flipped-Voltage-Follower low-dropout regulator) dari nol di proses TSMC 180nm CMOS.
Model harus sizing power transistor, tune compensation network, dan pilih bias voltage supaya enam metrics masuk spec bersamaan. Dalam sekitar satu jam iterasi closed-loop dengan ngspice, semua target metric tercapai — empat key metrics malah improve satu order of magnitude dari attempt awal.
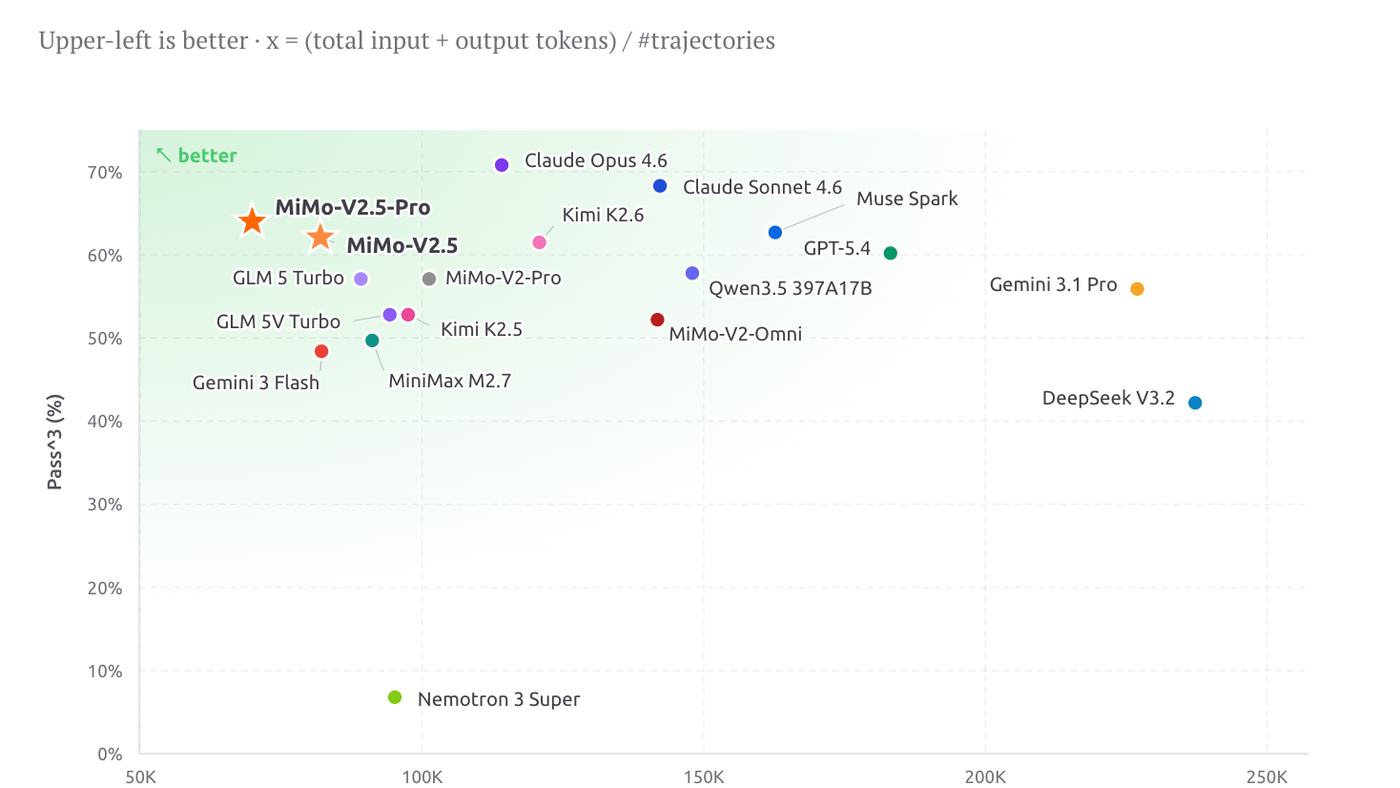
Intelligence level frontier cuma berguna kalau cost-effective. Di ClawEval, V2.5-Pro dapet 64% Pass^3 pakai cuma ~70K tokens per trajectory — sekitar 40-60% lebih hemat dari Claude Opus 4.6, Gemini 3.1 Pro, dan GPT-5.4 di level kemampuan yang sama.
Buat engineer yang bangun production agent pipelines, ini pengurangan cost yang material, bukan cuma angka marketing.
MiMo Coding Bench adalah evaluation suite internal Xiaomi buat ngetes model di real-world developer tasks dalam agentic frameworks kayak Claude Code. V2.5-Pro leading di benchmark ini, dan Xiaomi posisikan sebagai drop-in backend buat scaffolds termasuk Claude Code, OpenCode, dan Kilo.
Sementara V2.5-Pro target task agentic long-horizon paling sulit, MiMo-V2.5 adalah langkah besar di agentic capability dan multimodal understanding.
MiMo-V2.5 punya native visual dan audio understanding, reasoning seamless across modalities, surpass MiMo-V2-Pro di agentic performance, dan support sampai 1 juta tokens konteks.
Model ini di-design dari awal dengan perception dan action unified — trained to see, hear, and act on what it perceives. Ini arsitekturally significant karena multimodal model sebelumnya sering bolt vision di atas text backbone, bikin capability gaps di perception-action boundary.
Di sisi coding, value proposition-nya jelas: di MiMo Coding Bench, MiMo-V2.5 deliver hasil kuat di everyday coding tasks, closing gap dengan frontier models dan matching MiMo-V2.5-Pro dengan setengah cost.
Buat tim yang gak butuh extreme long-horizon depth V2.5-Pro, ini operating point yang compelling.
Di multimodal benchmarks: MiMo-V2.5 dapet 62.3 di Claw-Eval general subset, placing it at Pareto frontier of performance and efficiency. Di multimodal agentic subset, 23.8 di Claw-Eval Multimodal — matching Claude Sonnet 4.6, leading MiMo-V2-Omni 8 poin, trailing Claude Opus 4.6 1 poin.
Di video understanding, MiMo-V2.5 skor 87.7 di Video-MME, effectively tied dengan Gemini 3 Pro (88.4) dan well ahead of Gemini 3 Flash. Long-horizon video comprehension — scene tracking, temporal reasoning, visual grounding over minutes of footage — sekarang di frontier territory.
Di image understanding, MiMo-V2.5 81.0 di CharXiv RQ dan 77.9 di MMMU-Pro, closing in on Gemini 3 Pro.
Pricing-nya straightforward: MiMo-V2.5 di 1x (1 token = 1 credit), MiMo-V2.5-Pro di 2x (1 token = 2 credits). Token Plans gak charge multiplier lagi buat 1M-token context window — sebelumnya ini common cost friction buat long-context agentic workloads.
Jadi takeaway praktisnya apa buat kamu?
Pertama, MiMo-V2.5-Pro matching frontier closed-source models di key agentic benchmarks sambil pakai 40-60% fewer tokens per trajectory. Ini berarti cost production pipeline kamu bisa turun signifikan tanpa sacrifice capability.
Kedua, long-horizon autonomy udah real dan measurable. Model ini beneran bisa kerja otonom berjam-jam — nulis compiler lengkap atau video editor desktop — tanpa human in the loop.
Ketiga, MiMo-V2.5 adalah pilihan practical buat most use cases: native omnimodal, 1M context window, performance matching V2.5-Pro di everyday coding tasks dengan setengah harga.
Keempat, kedua model ini compatible dengan popular agentic scaffolds kayak Claude Code, OpenCode, dan Kilo — kasih kamu path drop-in, auditable, self-hostable ke frontier-level agentic AI.
Buat AI developers yang pengen lebih kontrol, transparansi, dan cost predictability, rilis ini worth explore. Open source gak lagi berarti compromise di performance.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

