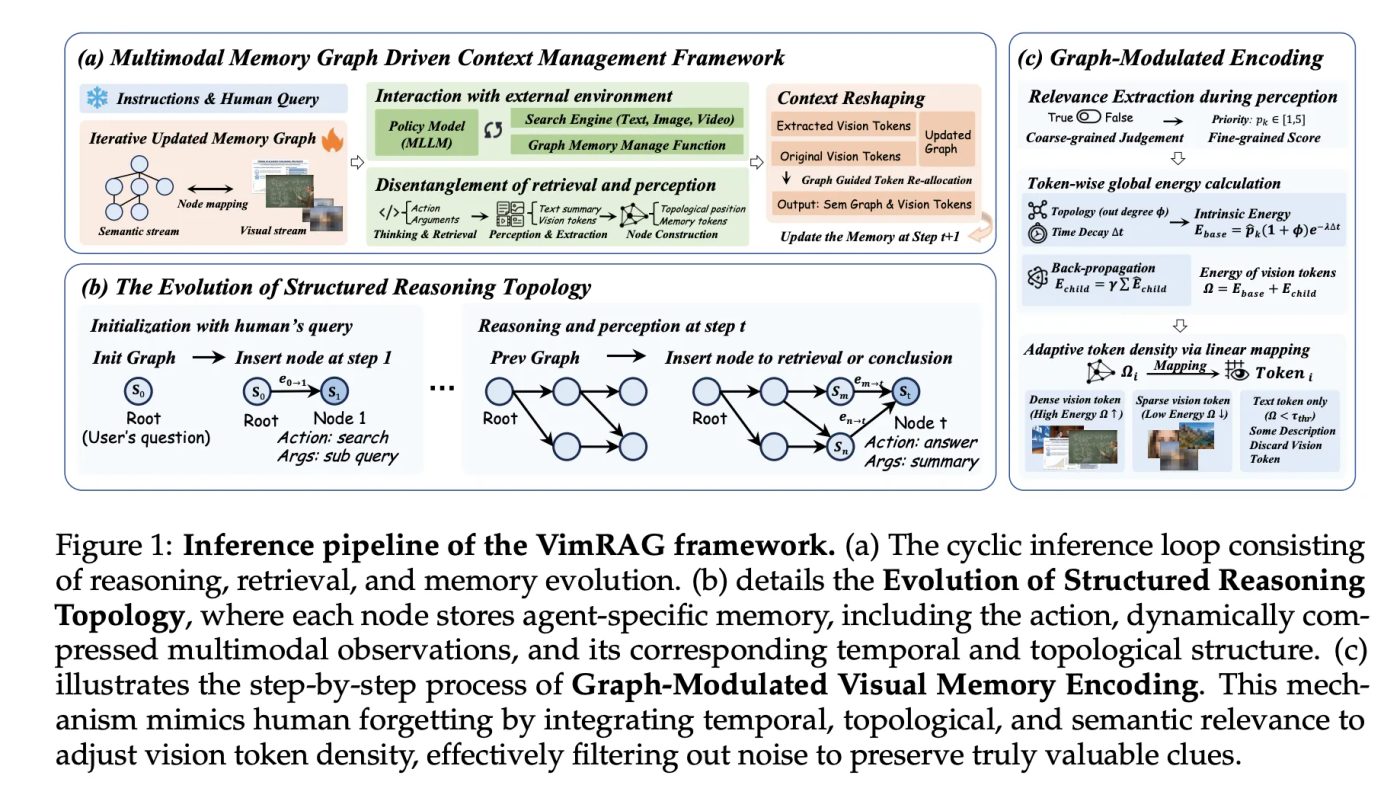
VimRAG dari Alibaba Tongyi Lab memperkenalkan pendekatan graph-based memory untuk Retrieval-Augmented Generation pada data visual, mengatasi keterbatasan metode linear dan kompresi memori tradisional.
Kamu pasti familiar dengan RAG atau Retrieval-Augmented Generation, teknik yang bikin AI lebih pintar dengan mengakses pengetahuan eksternal. Tapi begitu datanya bukan cuma teks—ada gambar dan video—sistem ini langsung kewalahan.
Data visual itu berat banget dalam token, padat informasinya rendah kalau dibanding query spesifik, dan cepet jadi kacau saat reasoning multi-step. Nah, tim riset Tongyi Lab dari Alibaba Group bikin solusi namanya VimRAG.
Masalah utamanya ada di dua tempat: history linear dan memori terkompresi. Kebanyakan agent RAG sekarang pakai loop Thought-Action-Observation atau ReAct, di mana semua interaksi disimpan jadi satu konteks yang terus membesar.
Bayangin kamu lagi analisis video panjang. Setiap langkah reasoning, history-nya makin gede, tapi informasi pentingnya malah makin tenggelam. Rasio informasi kritis jadi mendekati nol.
Solusi umumnya adalah kompresi memori, di mana observasi lama dirangkum jadi state ringkas. Ini bikin density stabil, tapi timbul masalah baru: Markovian blindness. Agent jadi lupa apa yang sudah di-query, akibatnya pencarian jadi berulang-ulang.
Dalam studi perbandingan menggunakan Qwen3VL-30B-A3B-Instruct, agent berbasis summarization sama-sama kena state blindness dengan ReAct. Tapi yang pakai graph-based memory? Redundant search-nya berkurang signifikan.
Studi kedua menguji empat strategi memori cross-modality. Pre-captioning paling irit token (0.9k) tapi akurasinya jeblok: 14.5% untuk image, 17.2% untuk video. Simpan visual token mentah? 15.8k token dengan noise yang overwhelming.
Context-aware captioning lebih baik (52.8% image, 39.5% video) tapi kehilangan detail fine-grained. Pemenangnya adalah Semantically-Related Visual Memory: cuma 2.7k token tapi capai 58.2% dan 43.7%.
Studi ketiga soal credit assignment menemukan fakta menarik: dalam trajectory positif, sekitar 80% langkah sebenarnya noise yang salah-salah dapat sinyal positif kalau pakai RL standar. Hapus langkah redundant dari trajectory negatif, performa malah pulih total.
Tiga temuan ini jadi fondasi VimRAG dengan tiga komponen utamanya.
Pertama, Multimodal Memory Graph. Bukan history datar atau ringkasan, tapi directed acyclic graph dinamis. Setiap node nyimpen struktur dependensi, sub-query, summary teks, dan bank memori episodik multimodal dari dokumen atau frame yang di-retrieve.
Policy-nya bisa pilih tiga aksi: a_ret untuk retrieval eksploratif, a_mem untuk persepsi multimodal dan populate memori, serta a_ans untuk terminal projection kalau evidence sudah cukup.
Untuk video, a_mem pakai kemampuan temporal grounding Qwen3-VL buat ekstrak keyframe yang aligned dengan timestamp sebelum masuk ke node.
Kedua, Graph-Modulated Visual Memory Encoding. Ini nganggap token assignment sebagai resource allocation problem. Setiap item visual dapet energy score berdasarkan semantic priority, node out-degree, dan temporal decay.
Energy final juga include reinforcement rekursif dari successor nodes, jadi node awal yang jadi fondasi reasoning berharga tetap terjaga. Token budget dialokasikan proporsional ke energy score dengan total budget S_total = 5 × 256 × 32 × 32.
Ketiga, Graph-Guided Policy Optimization atau GGPO. Ini perbaiki flaw fundamental dalam training agentic RAG: reward berbasis outcome salah-salah penalize good retrieval di trajectory gagal, dan reward redundant steps di trajectory sukses.
GGPO pakai struktur graph buat mask gradient yang misleading. Untuk sampel positif, dead-end nodes yang nggak di critical path di-mask. Untuk sampel negatif, langkah dengan retrieval relevan di-exclude dari negative policy gradient.
VimRAG diuji di sembilan benchmark: HotpotQA, SQuAD, WebQA, SlideVQA, MMLongBench, LVBench, WikiHowQA, SyntheticQA, dan XVBench yang baru dibuat tim riset dari HowTo100M.
Semua dataset digabung jadi unified corpus ~200k item multimodal interleaved, bikin evaluasi lebih challenging dan realistis. GVE-7B jadi embedding model untuk text, image, dan video retrieval.
Hasilnya? Di Qwen3-VL-8B-Instruct, VimRAG capai 50.1 vs 43.6 untuk Mem1 baseline terbaik sebelumnya. Di Qwen3-VL-4B-Instruct, 45.2 vs 40.6. SlideVQA 62.4 vs 55.7, SyntheticQA 54.5 vs 43.4.
Yang menarik, meski ada dedicated perception step, total trajectory length VimRAG justru lebih pendek dari ReAct dan Mem1. Struktur memori yang terorganisir mencegah repetitive re-reading dan invalid searches.
Practical takeaway buat kamu yang kerja dengan AI multimodal: jangan asal kompres data visual jadi teks kalau butuh detail. Pilih strategi memori yang selektif berdasarkan relevansi semantik. Dan kalau bangun agent reasoning, pertimbangkan struktur graph daripada linear history.
VimRAG nunjukkin bahwa cara kita struktur memori dan cara kita training agent itu sama pentingnya dengan model foundation-nya sendiri. Teknik ini bisa jadi referensi buat improve sistem RAG multimodal yang kamu bangun.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→