Metode TST Nous Research percepat training AI hingga 2.5x tanpa ubah arsitektur. Hemat waktu dan biaya training model besar.
Training AI model besar itu mahal banget, lho. Bahkan peningkatan efisiensi yang kecil bisa bikin kamu hemat waktu dan uang yang signifikan. Nah, Nous Research baru saja ngeluarin Token Superposition Training (TST), metode yang ngurangi waktu training AI tanpa ubah arsitektur model.
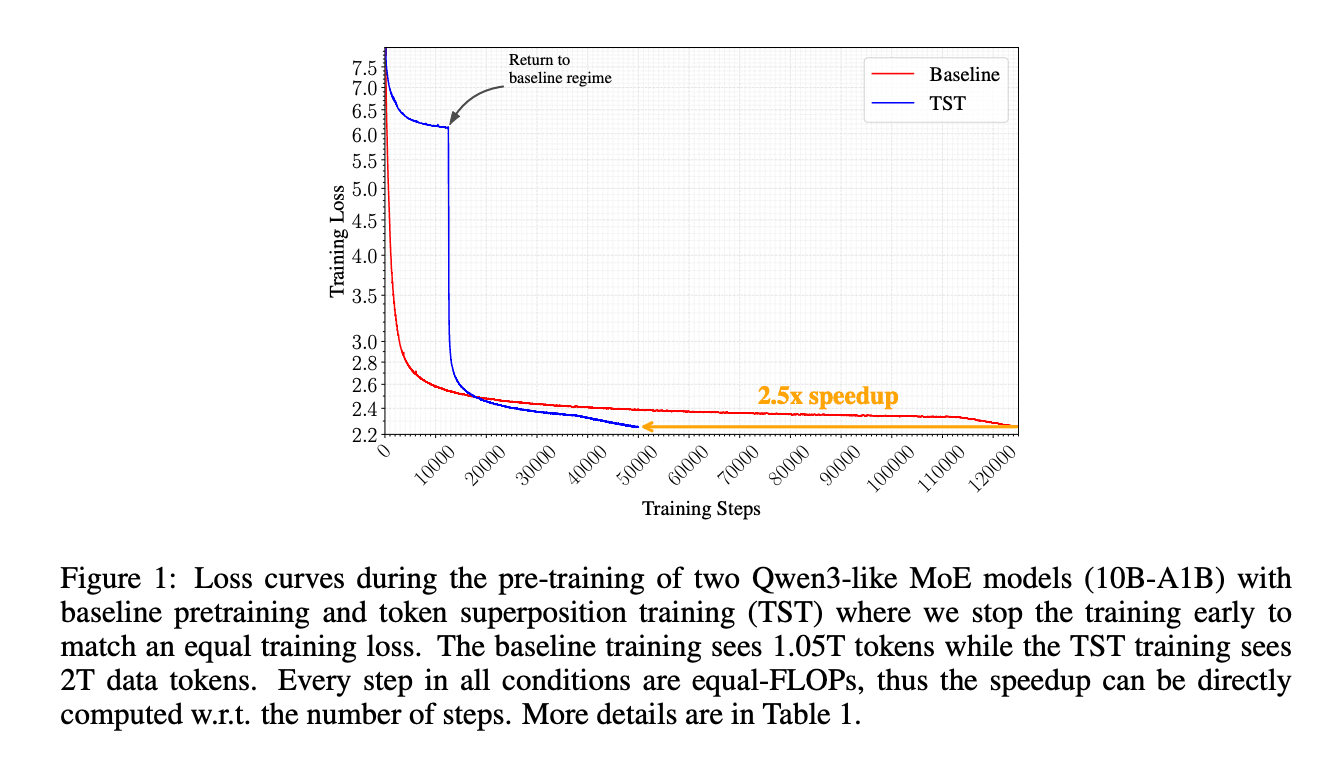
Di skala 10B-A1B mixture-of-experts, TST mencapai loss training yang lebih rendah daripada baseline dengan konsumsi 4,768 B200-GPU-hours, sementara baseline butuh 12,311. Artinya, kamu bisa hemat waktu training hingga 2.5x!
TST ini ngebantu masalah apa sih? Training AI modern itu heavily data-driven, bro. Training terus diluar dari optimal compute estimate. TST ini nanya, apakah throughput bisa ditingkatin lagi selama training, tanpa ubah tokenizer atau model secara permanen.
Advertisement
Slot in-article yang tampil setelah paragraf ketiga.
Caranya gampang banget, kok. TST punya dua fase berurutan: Fase 1 - Superposition: Untuk bagian awal training, model nggak dapet token individual. Input sequence dibagi jadi bag-bag berisi s token kontinu. Di layer embedding, setiap bag di-collapse jadi satu 's-token' dengan rata-rata embedding token.
Transformer kemudian proses sequence panjang L/s. Penting banget, setiap step TST dijaga sama-FLOPs dengan training biasa dengan nambah panjang data sequence s kali. Tiap posisi latent ngandung s token asli, jadi model makin banyak text per unit compute.
Di sisi output, setiap posisi latent prediksi next bag s token bukan single next token. Cross-entropy loss diganti jadi multi-hot cross-entropy (MCE) loss yang assign equal probability 1/s ke setiap token di target bag.
Fase 2 - Recovery: Setelah fase superposition, training lanjut dari checkpoint yang tersimpan dengan next-token prediction biasa untuk sisa steps. Kode TST dihapus total di batas fase buat nghindari kontaminasi eksperimental.
Ada loss spike sementara di transisi, biasanya antara 1-2 nats, tapi itu hilang dalam beberapa ribu step. Setelah itu, model recovered turun di bawah baseline dan stay di situ.
Model yang dihasilin di akhir Fase 2 identik arsitekturnya dengan model yang training biasa, sama behavior inference next-token prediction.
TST diuji di empat skala: 270M dan 600M dense, 3B dense, dan 10B-A1B MoE di Qwen3 family. Training pake dataset DCLM buat run kecil, dan 50/50 DCLM dan FineWeb-Edu buat MoE run.
Di skala 3B dengan bag size s=6 dan step ratio r=0.3, TST di 20,000 step dapet final loss 2.676 - hampir sama dengan baseline 36,000 step di 2.677 - tapi pake 247 B200-GPU-hours vs 443 baseline.
Di skala 10B-A1B MoE dengan s=16 dan r≈0.25, TST proses 2T data token dan dapet final loss 2.236, di bawah baseline 2.252 setelah 1.05T token, sambil unggul di semua benchmark yang di-report.
Peneliti punya tiga view perbandingan sama baseline - equal-FLOPs, equal-loss, dan equal-data. Di kondisi equal-FLOPs dan equal-loss, TST menang konsisten. Di total token consumption yang sama, baseline menang karena budget compute per data token TST lebih kecil.
Ada dua mekanisme terpisah di TST. Studi ablation isolasi komponen input dan output. Keduanya unggul dari baseline; gabungannya bikin improvement lebih lanjut tanpa tanda-tanda interference.
Mekanisme sisi output - next-bag-of-tokens prediction - related sama multi-token prediction (MTP). Tapi beda sama MTP yang nambah k independent prediction head dan extra parameter, TST keep single output head dan cuma ganti target.
Ini jadi member termurut dari kelas future-signal auxiliary objectives. Beda sama MTP, TST show consistent gains di semua skala termasuk model kecil dimana MTP udah ditunjukin degradasi performance.
Mekanisme sisi input nggak ada analog langsung di literature training terkini. Peneliti kasih dua penjelasan plausibel: mungkin secara implicit regularize embedding geometry, atau mungkin act sebagai pre-pre-training, exposing model ke coarser version real data sebelum fine-resolution language modeling mulai.
Studi ablation langsung test apa yang terjadi ketika representasi continuity broken. Peneliti run eksperimen 3B TST dimana input embedding dan output LM head di-reinitialize random di awal Fase 2.
Hasilnya: final loss loncat ke 2.938 - lebih buruk dari TST run (2.676) dan baseline biasa (2.808). Steps Fase 1 TST nggak contribute apa-apa ke final model. Ini confirm shared representations across both phases nggak kebetulan - itu yang bikin TST work.
Jadi intinya, TST ini metode super efektif buat ngecepat training AI model besar tanpa perlu ubah arsitektur. Cuma dengan rata-ratakan token dan ganti cara prediksi, kamu bisa hemat waktu training hingga 2.5x!
Practical takeaway: Kalau kamu lagi training AI model besar dan compute-bound, TST ini worth banget dicoba. Tapi ingat, TST lebih cocok buat training yang compute-bound, bukan data-bound. Karena di Phase 1, TST consume s× lebih banyak token.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→