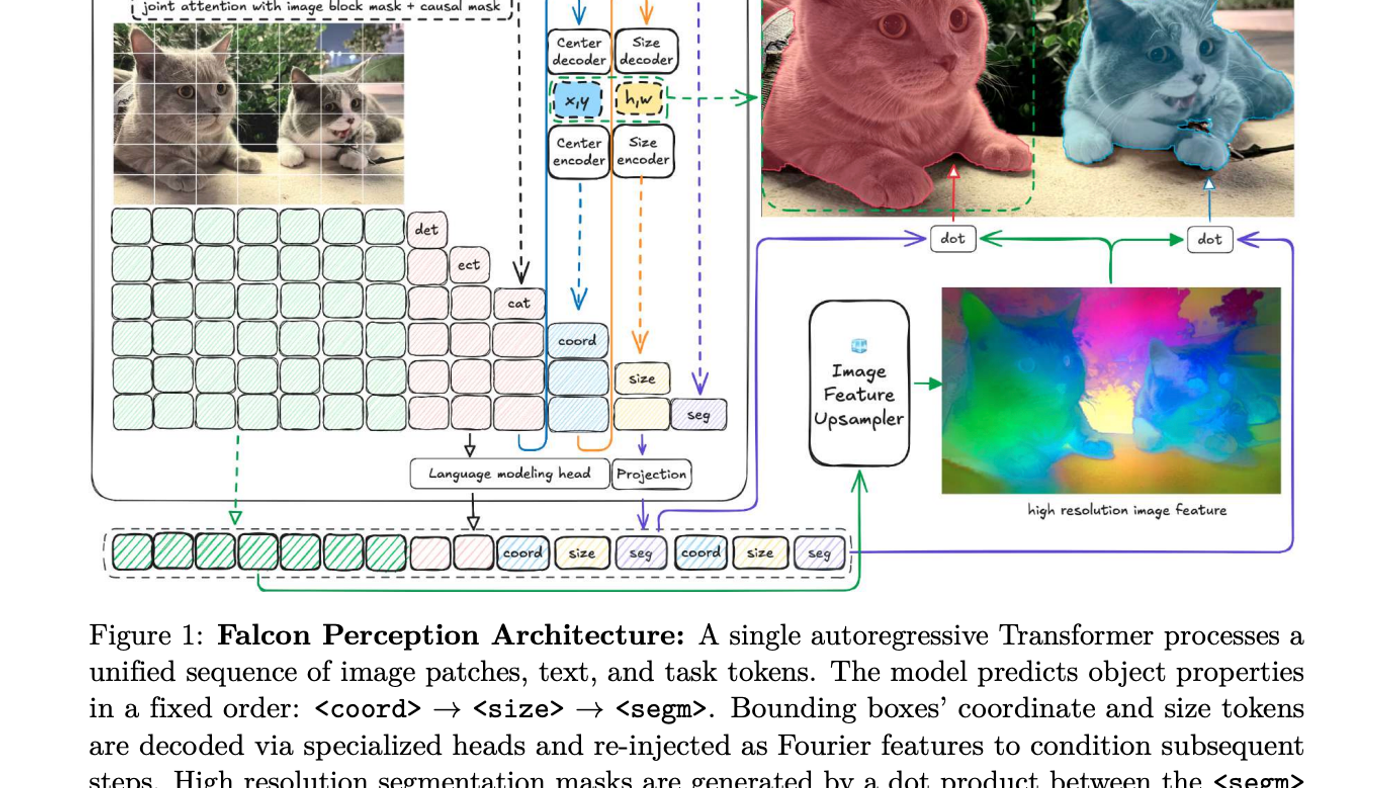
Falcon Perception dari TII adalah model early-fusion Transformer 600M parameter untuk open-vocabulary grounding dan segmentation. Pelajari arsitektur unified dan performanya yang mengungguli model besar.
Dunia computer vision selama ini mengandalkan pendekatan seperti LEGO: encoder vision terpisah dari decoder task. Cara ini memang berhasil, tapi bikin scaling jadi rumit dan interaksi bahasa-vision jadi terhambat.
Technology Innovation Institute (TII) punya solusi berbeda. Mereka rilis Falcon Perception, model Transformer dense 600 juta parameter yang menggabungkan semuanya dalam satu stack.
Yang menarik, model ini pakai early-fusion. Artinya, image patches dan text tokens diproses bersama dari layer pertama. Nggak ada lagi pemisahan encoder-decoder yang kaku.
Advertisement
Slot in-article yang tampil setelah paragraf ketiga.
Arsitekturnya disebut single stack for every modality. Satu Transformer belajar visual representation sekaligus melakukan task-specific generation. Efisien banget.
Falcon Perception pakai hybrid attention strategy. Image tokens saling attention secara bidirectional buat bangun global visual context. Sementara text dan task tokens pakai causal masking buat autoregressive prediction.
Buat jaga relasi spasial 2D, tim riset pakai 3D Rotary Positional Embeddings. Mereka sebut ini GGROPE (Golden Gate ROPE).
GGROPE memungkinkan attention heads melihat posisi relatif dari berbagai sudut. Hasilnya, model jadi robust terhadap rotasi dan variasi aspect ratio.
Format dasarnya simple: [Image] [Text] [coord] [size] [seg]. Model harus resolve spatial ambiguity dulu sebelum generate segmentation mask final.
Tim TII juga implementasi beberapa optimization buat training. Pertama, Muon optimizer untuk specialized heads (coordinates, size, segmentation). Hasilnya training loss lebih rendah dan benchmark performance lebih baik dari AdamW standar.
Kedua, FlexAttention dengan sequence packing. Gambar diproses di native resolution tanpa padding yang mubazir. Valid patches dipack ke fixed-length blocks, attention dibatasi per image sample.
Ketiga, raster ordering. Kalau ada multiple objects, model prediksi dari atas ke bawah, kiri ke kanan. Konvergensi lebih cepat dan coordinate loss lebih rendah dibanding random ordering.
Training-nya pakai multi-teacher distillation. Knowledge dari DINOv3 (ViT-H) untuk local features dan SigLIP2 (So400m) untuk language-aligned features. Total training mencapai ~685 Gigatokens dalam tiga stage.
Stage pertama: In-Context Listing (450 GT). Model belajar 'list' inventory scene buat bangun global context.
Stage kedua: Task Alignment (225 GT). Transisi ke independent-query tasks dengan Query Masking. Jamin model grounding setiap query hanya berdasarkan image.
Stage ketiga: Long-Context Finetuning (10 GT). Adaptasi singkat untuk extreme density, mask limit dinaikkan sampai 600 per expression.
Buat evaluasi, TII bikin PBench. Benchmark ini organize samples ke lima level semantic complexity: Simple Objects, Attributes, OCR-Guided, Spatial Understanding, dan Relations.
Hasilnya? Falcon Perception 600M mengungguli SAM 3 di hampir semua kategori. Paling mencolok di Spatial Understanding (L3): +21.9 poin. Di Relations (L4): +15.8 poin. Dense split overall: 72.6 vs 58.4.
TII juga extend arsitektur ini ke FalconOCR, model 300M parameter khusus document. Hasilnya competitive dengan sistem OCR proprietary yang jauh lebih besar.
Di olmOCR, FalconOCR dapat 80.3% accuracy. Ini match atau exceed Gemini 3 Pro (80.2%) dan GPT 5.2 (69.8%). Di OmniDocBench: 88.64, ahead of GPT 5.2 (86.56) dan Mistral OCR 3 (85.20).
Practical takeaway buat kamu: unified architecture dengan early-fusion bisa lebih efisien dan powerful daripada pendekatan modular. Falcon Perception bukti bahwa 600M parameter dengan desain yang tepat bisa mengungguli model besar yang terfragmentasi.
Kalau kamu kerja di computer vision atau multimodal AI, pertimbangkan arsitektur early-fusion untuk project berikutnya. Potensi scaling dan integrasi bahasa-vision jauh lebih seamless.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini direwrite dari sumber MarkTechPost. Kamu bisa cek versi aslinya di https://www.marktechpost.com/2026/04/03/tii-releases-falcon-perception-a-0-6b-parameter-early-fusion-transformer-for-open-vocabulary-grounding-and-segmentation-from-natural-language-prompts/.
