Sakana AI Introduces KAME: A Tandem Architecture That Injects Real-Time LLM Knowledge Into Speech-to-Speech Conversational AI Without Adding Latency The p…
MarkTechPost lagi ngeluarin cerita yang cukup penting: Sakana AI Introduces KAME: A Tandem Architecture That Injects Real-Time LLM Knowledge Into Speech-to-Speech Conversational AI Without Adding Latency The post Sakana AI Introduces KAME: A Tandem Speech-to-Speech Architecture That Injects LLM Knowledge in Real Time appeared first on MarkTechPost .. Buat AI, ini biasanya bukan cuma soal model atau demo baru, tapi soal arah product strategy. Kalau lo ngikutin ai updates, cerita kayak gini sering jadi tanda bahwa batas antara “eksperimen” dan “alat kerja harian” makin tipis.
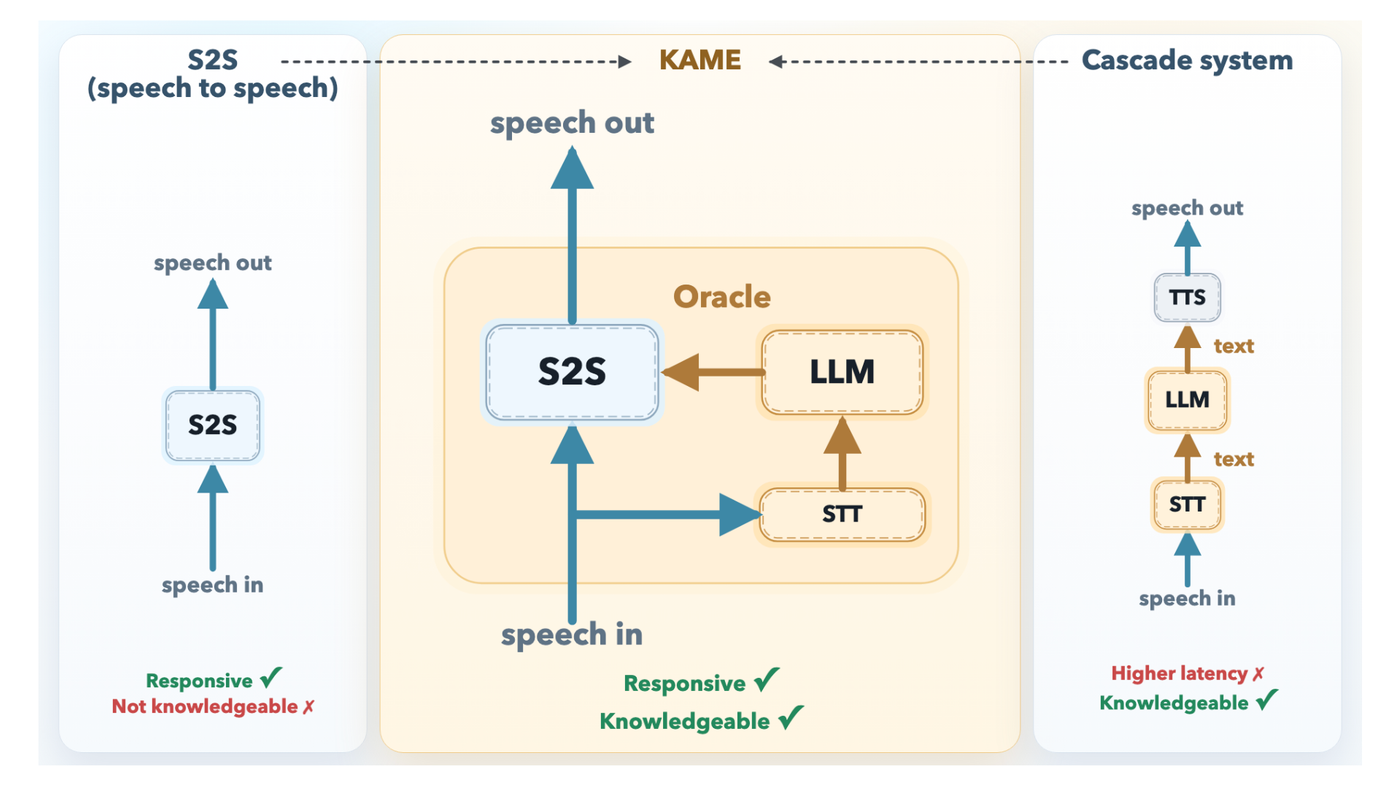
Kalau kita lihat lebih jauh, The fundamental tension in conversational AI has always been a binary choice: respond fast or respond smart. Real-time speech-to-speech (S2S) models — the kind that power natural-feeling voice assistants — start talking almost instantly, but their answers tend to be shallow. Cascaded systems that route speech through a large language model (LLM) are far more knowledgeable, but the pipeline delay is long enough to make conversation feel stilted and robotic. Researchers at Sakana AI, the Tokyo-based AI lab introduces KAME (Knowledge-Access Model Extension), a hybrid architecture that keeps the near-zero response latency of a direct S2S system while injecting the richer knowledge of a back-end LLM in real time. The Problem: Two Paradigms, Two Tradeoffs To understand why KAME is important, it helps to understand the two dominant designs it bridges. A direct S2S model like Moshi (developed by KyutAI) is a monolithic transformer that takes in audio tokens and produces audio tokens in a continuous loop. Because it doesn’t need to synchronize with external systems, its response latency is exceptionally low — for many queries, the model starts speaking before the user even finishes their question. But because acoustic signals are far information-denser than text, the model has to spend significant capacity modeling paralinguistic features like tone, emotion, and rhythm. That leaves less room for factual knowledge and deep reasoning. A cascaded system, by contrast, routes the user’s speech through an Automatic Speech Recognition (ASR) model, feeds the resulting text into a powerful LLM, and then converts the LLM’s response back into speech via a Text-to-Speech (TTS) engine. The knowledge quality is excellent — you can plug in any frontier LLM — but the system must wait for the user to finish speaking before ASR and LLM processing can even begin. The result is a median latency of around 2.1 seconds, which is long enough to noticeably interrupt natural conversational flow. https://pub.sakana.ai/kame/ KAME’s Architecture: Speaking While Thinking KAME operates as a tandem system with two asynchronous components running in parallel. The front-end S2S module is based on the Moshi architecture and processes audio in real time at the cycle of discrete audio tokens (approximately every 80 milliseconds). It begins generating a spoken response immediately. Internally, Moshi’s original three-stream design — input audio, inner monologue (text), and output audio — is extended in KAME with a fourth stream: the oracle stream . This is the key innovation point. The back-end LLM module consists of a streaming speech-to-text (STT) component paired with a full-scale LLM. As the user speaks, the STT component continuously builds a partial transcript and periodically sends it to the back-end LLM. For each partial transcript it receives, the LLM generates a candidate text response — called an oracle — and streams it back to the front-end. Because the user’s speech is still arriving, these oracles start as educated guesses and become progressively more accurate as the transcript grows more complete. The front-end S2S transformer then conditions its ongoing speech output on both its own internal context and these incoming oracle tokens. When a new, better oracle arrives, the model can correct course — effectively updating its response mid-sentence, the way a human might. Because both modules run asynchronously and independently, the initial response latency stays near zero. Training on Simulated Oracles One challenge is that no naturally occurring dataset contains oracle signals. Sakana AI research team addresses this with a technique called Simulated Oracle Augmentation . Using a ‘simulator’ LLM and a standard conversational dataset (user utterance + ground-truth response), the research team generates synthetic oracle sequences that mimic what a real-time LLM would produce across different levels of transcript completeness. They define six hint levels (0–5), ranging from a completely unguided guess at hint level 0 to the verbatim ground-truth response at hint level 5. The training data for KAME was built from 56,582 synthetic dialogues drawn from MMLU-Pro, GSM8K, and HSSBench, converted to audio via TTS and augmented with these progressive oracle sequences. Results: Near-Cascaded Quality, Near-Zero Latency Evaluations on a speech-synthesized subset of the MT-Bench multi-turn Q&A benchmark — specifically the reasoning, STEM, and humanities categories (Coding, Extraction, Math, Roleplay, and Writing were excluded as unsuitable for speech interaction) — show a dramatic improvement. Moshi alone scores 2.05 on average. KAME with gpt-4.1 as the back-end scores 6.43, and KAME with claude-opus-4-1 as the back-end scores 6.23 — both at essentially the same latency as Moshi. The leading cascaded system, Unmute (also backed by gpt-4.1), scores 7.70, but with a median latency of 2.1 seconds versus near-zero for KAME. To isolate back-end capability from timing effects, the research team also evaluated the back-end LLM’s text responses from the final oracle injection in each KAME session directly — bypassing the premature-generation problem entirely. Those scores averaged 7.79 (reasoning 6.48, STEM 8.34, humanities 8.56), comparable to Unmute’s 7.70. This confirms that KAME’s gap to cascaded systems is not a ceiling on the back-end LLM’s knowledge, but a consequence of starting to speak before the full user query has been heard. Crucially, KAME is fully back-end agnostic . The front-end was trained using gpt-4.1-nano as the primary back-end, but swapping in claude-opus-4-1 or gemini-2.5-flash at inference time requires no retraining. In Sakana AI’s experiments, claude-opus-4-1 tended to outperform gpt-4.1 on reasoning tasks, while gpt-4.1 scored higher on humanities questions — suggesting practitioners can route queries to the most task-appropriate LLM without touching the front-end model. Key Takeaways KAME bridges the speed-vs-knowledge tradeoff in conversational AI by running a front-end speech-to-speech model and a back-end LLM asynchronously in parallel — the S2S model responds immediately while the LLM continuously injects progressively refined ‘oracle’ signals in real time, shifting the paradigm from ‘think, then speak’ to ‘speak while thinking.’ The performance gains are substantial without any latency cost — KAME raises the MT-Bench score from 2.05 (Moshi baseline) to 6.43, approaching the cascaded system Unmute’s 7.70, while maintaining near-zero median response latency versus Unmute’s 2.1 seconds. The architecture is fully back-end agnostic — the front-end was trained using gpt-4.1-nano but supports plug-and-play swapping of any frontier LLM (gpt-4.1, claude-opus-4-1, gemini-2.5-flash) at inference time with no retraining, enabling task-specific LLM selection based on domain strengths. Check out the Model Weights , Paper , Inference code and Technical details . Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter . Wait! are you on telegram? now you can join us on telegram as well. Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us The post Sakana AI Introduces KAME: A Tandem Speech-to-Speech Architecture That Injects LLM Knowledge in Real Time appeared first on MarkTechPost . ngasih petunjuk tentang apa yang lagi dicari pasar: speed, reliability, dan output yang bisa diukur. Di AI, yang menang bukan yang paling heboh ngomongin capability, tapi yang paling gampang dipakai tim buat nyelesaiin kerjaan nyata.
Research tambahan ngasih konteks yang lebih tajam: Research lookup returned no usable results.. Ini bikin pembacaan awal jadi lebih grounded, bukan cuma bergantung ke judul atau ringkasan feed. Kalau ada detail yang saling nambah, gue pakai itu buat bikin cerita ini lebih utuh dan lebih berguna buat lo.
Di level produk dan operasional, cerita kayak gini biasanya nunjukin satu hal: perusahaan yang lebih cepat belajar bakal punya advantage. Kalau workflow makin otomatis, tim yang masih manual kebanyakan bakal kalah gesit. Kalau distribusi makin ketat, brand yang punya channel kuat bakal lebih unggul. Jadi meskipun judulnya kelihatan khusus, implikasinya sering masuk ke area yang jauh lebih dekat ke keputusan bisnis sehari-hari daripada yang orang kira.
Ada juga layer kompetisi yang sering kelewat. Begitu satu pemain besar bergerak, pemain kecil biasanya punya dua pilihan: ikut naik level atau makin susah relevan. Itu sebabnya gue suka lihat berita bukan sebagai peristiwa tunggal, tapi sebagai bagian dari pola. Siapa yang bergerak duluan? Siapa yang nunggu? Siapa yang bisa mengeksekusi lebih rapi? Dari situ biasanya kebaca apakah sebuah tren masih hype atau udah mulai jadi infrastruktur.
Buat pembaca yang peduli ke hasil praktis, pertanyaan yang paling berguna bukan “apakah ini keren?” tapi “apa yang harus gue ubah setelah baca ini?”. Kalau lo founder, bisa jadi jawabannya ada di positioning, pricing, atau channel distribusi. Kalau lo trader, mungkin yang perlu dipantau adalah sentimen, momentum, dan apakah pasar udah overreact. Kalau lo cuma pengin update cepat, minimal lo jadi ngerti kenapa topik ini muncul dan kenapa orang lain mulai ngomongin sekarang.
Gue juga sengaja ngasih ruang buat konteks yang sedikit lebih tenang, karena berita yang rame sering bikin orang lompat ke kesimpulan terlalu cepat. Tidak semua headline berarti revolusi. Kadang ada yang cuma noise, kadang ada yang benar-benar awal perubahan. Bedanya ada di konsistensi tindak lanjutnya. Kalau dalam beberapa siklus berikutnya topik ini terus muncul, besar kemungkinan kita lagi lihat pergeseran yang serius, bukan sekadar buzz harian.
Jadi kalau lo minta versi pendeknya: Sakana AI Introduces KAME: A Tandem Speech-to-Speech Architecture That Injects LLM Knowledge in Real Time penting bukan karena judulnya doang, tapi karena dia nunjukin arah pergerakan yang bisa berdampak ke cara orang bikin produk, baca pasar, dan nyusun strategi. Buat gue, itu inti yang paling worth it untuk dibawa pulang. Sisanya bisa lo simpan sebagai detail, tapi arah besarnya udah cukup jelas: pergeseran ini layak dipantau, bukan di-skip.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→