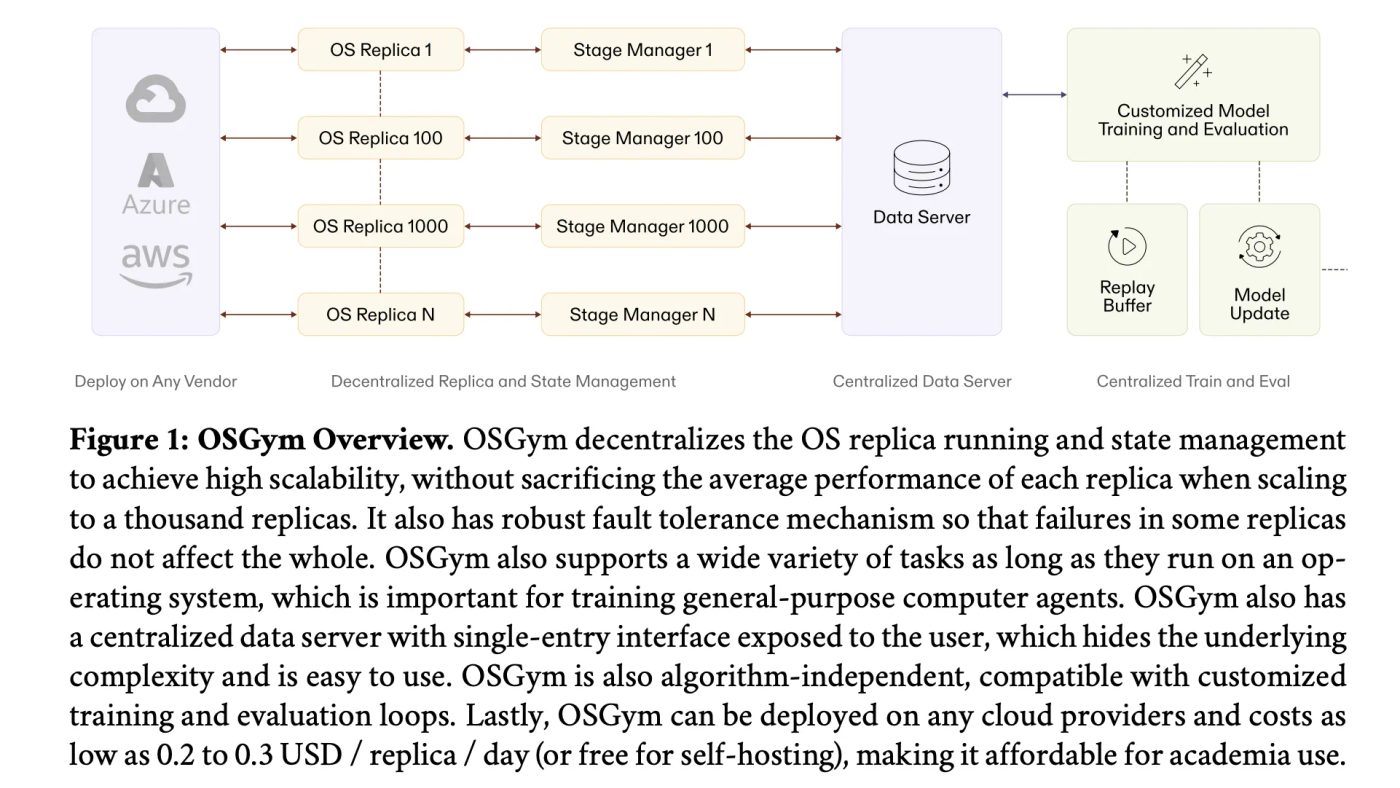
OSGym adalah framework infrastruktur baru untuk riset computer use agent. Bisa kelola 1.000+ OS replicas cuma $0.23/hari dengan optimasi RAM, copy-on-write disk, dan state management terdistribusi.
Bayangin kamu lagi training AI yang bisa beneran pakai komputer — buka aplikasi, klik tombol, browsing, sampai nulis kode. Keren kan? Tapi tau nggak, ini salah satu masalah infrastruktur paling susah di dunia AI modern.
Bukan masalah data. Bukan masalah model. Ini masalah 'plumbing'-nya. Kamu butuh ratusan atau ribuan sistem operasi lengkap dengan GUI yang jalan barengan. Tiap sistem harus bisa handle crash yang nggak bisa diprediksi. Dan yang paling penting: biayanya nggak boleh bikin lab riset universitas bangkrut.
Nah, dari situ lahir OSGym. Tim riset dari MIT, UIUC, CMU, USC, UVA, dan UC Berkeley bikin framework ini buat nyelesain masalah tersebut.
Sebelum lanjut, kita perlu paham dulu apa itu computer use agent. Beda sama chatbot yang cuma bales teks, computer use agent itu AI yang bisa lihat screenshot desktop, mikir mau ngapain, terus eksekusi — klik, ngetik, buka file — persis kayak manusia.
Contoh komersialnya ada Claude Computer Use dari Anthropic sama Operator dari OpenAI. Di sisi riset, ada UI-TARS, Agent-S2, dan CogAgent yang terus nge-push batasannya.
Tapi training sistem kayak gini butuh data interaksi masif yang dihasilkan di dalam environment OS beneran. Dan di sinilah semuanya jadi mahal dan rumit.
Sandbox buat coding atau browser itu relatif ringan. Tapi sandbox OS lengkap dengan GUI? Nggak sama sekali. Tiap VM butuh disk bootable sekitar 24 GB, alokasi CPU dan RAM sendiri, plus display stack.
Kaliin itu ratusan atau ribuan instance yang jalan paralel. Kamu bakal punya masalah konsumsi resource yang budget riset akademik biasanya nggak sanggup tanggung.
Belum lagi masalah reliabilitas. Software crash. Session browser timeout. Aplikasi freeze. Kalau pipeline training kamu nggak handle kegagalan ini dengan elegan, satu VM bermasalah bisa bikin seluruh training batch macet.
OSGym nyelesain kedua masalah ini dengan empat optimasi arsitektur yang beda.
Pertama, decentralized OS state management. Cara naifnya adalah pakai satu manager sentral buat semua replica. Tapi ini single point of failure — makin banyak replica, makin overwhelmed manager-nya, latency naik, dan satu crash bisa hentikan seluruh sistem.
OSGym kasih tiap OS replica manager sendiri. Tiap manager expose method kayak OpenAI Gym API — reset, step, shutdown — tapi handle health monitoring dan crash recovery sendiri. Gagal di satu replica nggak nyebar ke yang lain.
Kedua, hardware-aware OS replica orchestration. Ini insight menarik: bottleneck-nya tergantung berapa replica yang kamu pack per mesin.
Replica sedikit per server (K kecil), sistem dibatasi CPU — semua replica berebut waktu prosesor. Tapi kalau kamu pack lebih banyak replica per server (K besar), bottleneck-nya pindah ke RAM. Dan RAM itu jauh lebih murah dari CPU.
Modul RAM 32 GB DDR4 biasanya cuma 10-20% harga CPU 16-core. OSGym jalanin replica sebagai Docker container, bukan VM penuh, buat nurunin overhead per-replica.
Dengan pilih server RAM gede dan jalanin lebih banyak replica per mesin, biaya harian turun dari ~$300 buat 128 replica di K=1, jadi sekitar $30 di K=64 — sekitar $0.234 per replica per hari. Angka yang masuk akal buat banyak grant akademik.
Ketiga, KVM virtualization dengan copy-on-write disk management. Masalah provisioning disk diselesain pakai teknik filesystem namanya reflink copy-on-write (CoW).
Biasanya, nyalain 128 VM berarti duplikat image base 24 GB sebanyak 128 kali — lebih dari 3 TB storage dan 30 detik provisioning per VM. OSGym pakai cp --reflink=always di drive NVMe format XFS.
Tiap disk image VM berbagi physical disk blocks sama image base, dan cuma alokasi block baru kalau VM beneran nulis. Hasilnya: 128 VM cuma konsumsi 366 GB physical disk, bukan 3.1 TB — pengurangan 88% — dan waktu provisioning disk turun dari 30 detik jadi 0.8 detik per VM, 37× lebih cepat.
Tiap VM tetap lihat disk logikal 24 GB penuh dengan performa CPU hampir native.
Keempat, robust container pool dengan multi-layer fault recovery. OSGym maintain runner pool yang pre-warmed — defaultnya 128 runner per executor node — diinisialisasi sebelum training mulai.
Daripada bikin dan hancurin VM on-demand, runner di-recycle antar task. Sebelum tiap pembuatan VM, OSGym baca /proc/meminfo dan /proc/loadavg buat verifikasi host bisa handle instance baru, blokir pembuatan kalau memory tersisa di bawah 10% atau kurang dari 8 GB absolut.
Tiap container di-limit memory 6 GB buat mencegah over-provisioning saat burst. Sistem juga tune parameter kernel Linux yang biasanya bikin silent failure saat concurrency tinggi — misalnya fs.aio-max-nr dinaikin dari 65.536 jadi 1.048.576, dan fs.inotify.max_user_instances dari 128 jadi 8.192.
Fault recovery jalan di dua level: di level step, tiap action dapat default 10 kali retry; di level task, kalau runner gagal permanen, task otomatis dipindah ke runner fresh.
Ada dua elemen desain penting buat developer yang mau integrasi OSGym. Pertama, tiap task ikuti unified execution flow empat fase — Configure, Reset, Operate, Evaluate — terlepas dari software atau domain-nya.
Standardisasi ini bikin gampang nambahin task type baru tanpa ubah infrastruktur sekitarnya. Kedua, di atas replica layer, centralized data server Python class expose single-entry batched interface (__next__ dan async_step) yang sembunyiin semua kompleksitas komunikasi state manager dan queuing.
Method batched step-nya asynchronous, artinya training loop nggak pernah keblokir nunggu OS replica selesai eksekusi action.
Gimana hasil praktisnya? Pakai 1.024 OS replica paralel, sistem ngumpulin trajectory di sepuluh kategori task — termasuk LibreOffice Writer, Calc, Impress, Chrome, ThunderBird, VLC, VS Code, GIMP, konfigurasi sistem OS, dan multi-app workflows — dengan kecepatan sekitar 1.420 trajectory per menit.
Tanpa paralelisasi, butuh 115.654 detik. Seluruh dataset cuma habis $43 di cloud compute.
Tim riset terus pakai data itu buat fine-tune Qwen2.5-VL 32B via supervised fine-tuning, diikuti reinforcement learning pakai pipeline PPO-based semi-online asynchronous (200 step, batch size 64, learning rate 1e-6).
Model hasilnya dapet success rate 56,3% di benchmark OSWorld-Verified — kompetitif dengan metode existing untuk base model 32B parameter tanpa task-specific tuning.
Jadi apa takeaway praktisnya buat kamu yang mau riset di bidang ini?
Pertama, training computer use agent itu masalah infrastruktur dulu. OS sandbox lengkap dengan GUI jauh lebih berat dari environment coding atau browser — tiap VM butuh ~24 GB disk, CPU dan RAM dedicated, plus display stack. Tanpa optimasi hati-hati, scale ke ratusan replica simply nggak terjangkau buat kebanyakan lab akademik.
Kedua, RAM itu pengungkit scaling yang lebih pintar dari CPU. Orchestration hardware-aware OSGym nunjukkin kalau pack lebih banyak replica per server mindahin bottleneck dari CPU ke RAM — dan RAM 5-10× lebih murah. Insight ini sendiri motong biaya per-replica dari ~$2.10/hari jadi serendah $0.23/hari.
Ketiga, copy-on-write disk management ilangin storage wall. Dengan XFS reflink CoW (cp --reflink=always), OSGym nurunin konsumsi disk fisik 88% dan percepat provisioning disk VM 37× — dari masalah 3.1 TB, 30 detik per VM jadi 366 GB, 0.8 detik.
Keempat, decentralized state management itu kunci robustness di scale. Kasih tiap OS replica manager sendiri artinya failure tetap terisolasi. Bahkan mulai dari state crash penuh, OSGym bisa self-recover semua replica dalam waktu singkat — kritis buat training job panjang yang nggak boleh terputus.
Kelima, riset computer use agent di scale akademik sekarang financially viable. Dengan 1.024 replica yang generate 1.420 trajectory per menit dan full dataset yang cuma $43 di cloud compute, OSGym bawa biaya infrastruktur training computer use agent general-purpose ke jangkauan budget riset universitas.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→