Sapiens2 dari Meta AI adalah model vision generasi baru untuk analisis tubuh manusia dengan resolusi hingga 4K, mendukung pose estimation, segmentasi, dan estimasi geometri 3D.
Pernah lihat sistem motion capture gagal mendeteksi jari-jari tangan? Atau model segmentasi yang bingung membedakan gigi dengan gusi? Itulah kenapa computer vision untuk manusia itu susah.
Manusia bukan objek biasa. Ada struktur sendi yang kompleks, detail permukaan halus, plus variasi besar dalam pose, pakaian, pencahayaan, dan etnisitas. Bikin model yang paham semua ini sekaligus? Benar-benar challenging.
Meta AI baru saja merilis Sapiens2, generasi kedua dari keluarga model foundation untuk human-centric vision. Model ini dilatih dengan dataset baru berisi 1 miliar gambar manusia, dengan ukuran model dari 0.4B sampai 5B parameter.
Yang menarik, Sapiens2 dirancang untuk bekerja di resolusi native 1K, dengan varian hierarkis yang mendukung hingga 4K. Ini loncatan besar dari generasi sebelumnya di hampir semua benchmark.
Generasi pertama Sapiens mengandalkan Masked Autoencoder (MAE) untuk pretraining. MAE bekerja dengan menutupi 75% patch gambar, lalu melatih model untuk merekonstruksi pixel yang hilang.
Cara ini efektif untuk belajar detail spasial dan tekstur, berguna untuk task seperti segmentasi atau depth estimation. Tapi ada masalah: MAE belajar terutama lewat kompresi, bukan semantik tingkat tinggi.
MAE bisa bilang sesuatu "seperti apa", tapi tidak necessarily "apa artinya" dalam konteks tubuh manusia. Di sinilah contrastive learning (CL) seperti DINO dan SimCLR unggul: mereka mengorganisir representasi secara semantik.
Tapi CL punya tradeoff-nya sendiri. Augmentasi agresif seperti color jitter dan blurring bisa menghilangkan cue penting seperti skin tone atau kondisi pencahayaan. Ini yang tim riset sebut representation drift.
Sapiens2 mengatasi ini dengan menggabungkan kedua objective: masked image reconstruction loss untuk preservasi low-level fidelity, plus global contrastive loss menggunakan framework student-teacher berbasis DINOv3.
Yang krusial, color augmentations tidak diterapkan pada global views untuk objective MAE, sehingga appearance cues tetap terjaga untuk task fotorealistik.
Untuk mendapatkan 1 miliar gambar training yang berkualitas, tim Meta menerapkan pipeline filtering multi-tahap. Dari pool sekitar 4 miliar gambar web-scale, mereka lakukan bounding box detection, head-pose estimation, aesthetic scoring, CLIP-based filtering, dan deteksi text-overlay.
Hasilnya adalah corpus terkurasi di mana setiap gambar memuat minimal satu orang prominent dengan resolusi short-side minimum 384 pixel. Deduplication dilakukan dengan perceptual hashing dan deep-feature nearest-neighbor pruning.
Tim juga melakukan clustering pada visual embeddings dan selective sampling untuk menyeimbangkan dataset across poses, viewpoints, occlusion levels, clothing types, dan lighting conditions. Tidak ada task labels atau human-specific priors yang dimasukkan selama pretraining.
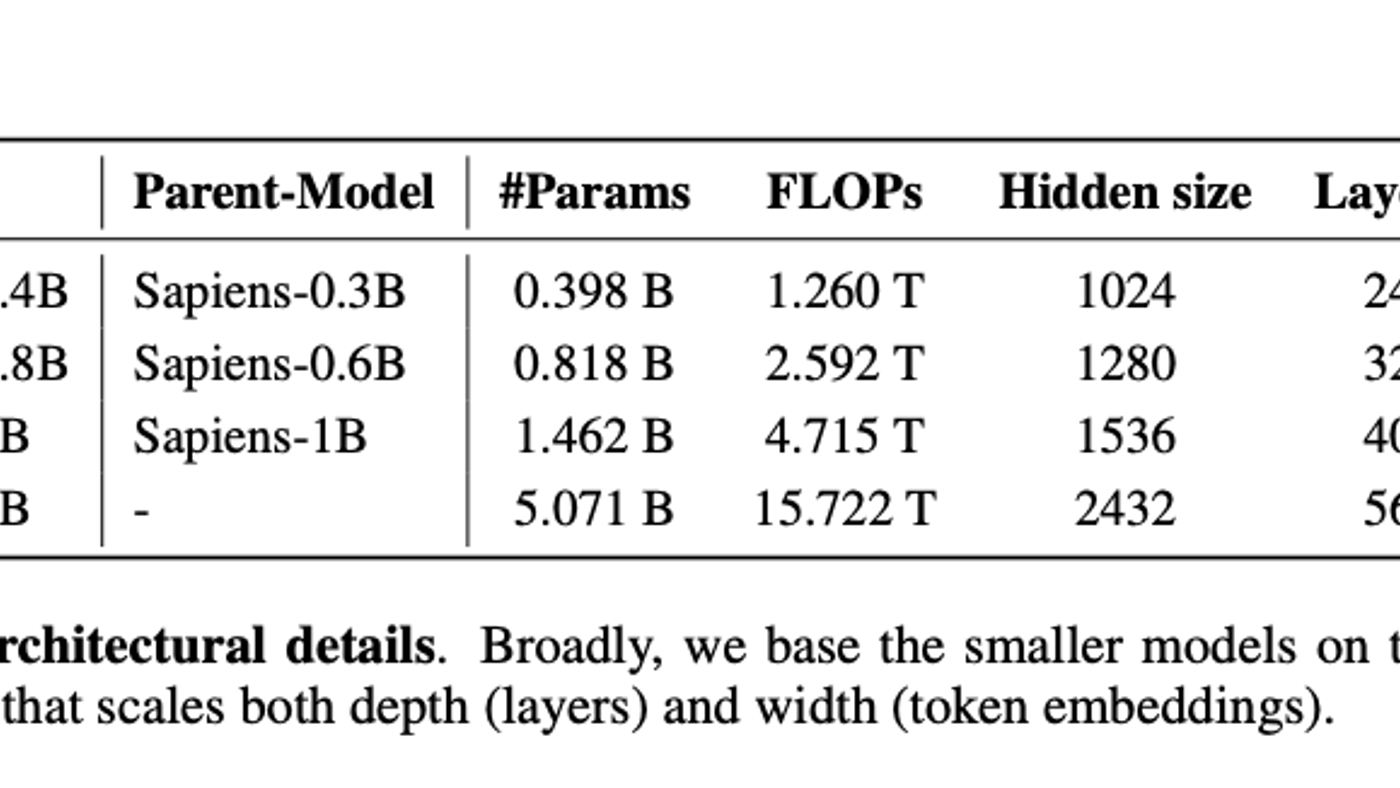
Sapiens2 hadir dalam empat ukuran: 0.4B, 0.8B, 1B, dan 5B parameter, semua di resolusi native 1K. Model 5B ini adalah vision transformer dengan FLOPs tertinggi yang dilaporkan sampai saat ini: 15.722 TFLOPs.
Untuk resolusi 4K, tim mengadopsi hierarchical windowed attention design. Layer pertama K menerapkan windowed self-attention secara lokal untuk capture fine texture dan boundaries. Kemudian [CLS]-guided pooling menurunkan resolusi token grid, dan layer L selanjutnya menerapkan global self-attention.
Design ini compatible dengan MAE-style pretraining karena masked tokens bisa didrop setelah local stage, mencegah information leak across masked regions.
Setelah pretraining, backbone difine-tune untuk lima downstream task dengan task-specific heads yang lightweight: Pose Estimation (308 keypoint full-body skeleton), Body-Part Segmentation (29 kelas semantik), Pointmap Estimation (per-pixel 3D pointmap), Normal Estimation (surface unit normals), dan Albedo Estimation (diffuse albedo untuk recover true skin tone).
Skala supervision untuk task-specific meningkat 10× dari generasi sebelumnya, biasanya mencapai sekitar 1 juta labels per task. Untuk pose estimation saja, tim menganotasi 100K in-the-wild images baru untuk melengkapi studio capture data.
Hasilnya impressive. Pada pose test set 11K gambar in-the-wild, Sapiens2-5B mencapai 82.3 mAP versus 78.3 mAP untuk Sapiens-2B. Peningkatan +4 mAP.
Untuk body-part segmentation, bahkan model terkecil Sapiens2-0.4B sudah mencetak 79.5 mIoU (+21.3 dari Sapiens-2B*), sementara Sapiens2-5B mencapai 82.5 mIoU. Varian 4K, Sapiens2-1B-4K, mendorong segmentation ke 81.9 mIoU dan 92.0 mAcc.
Pada surface normal estimation, Sapiens2-0.4B sudah mencapai mean angular error 8.63°, mengungguli state-of-the-art sebelumnya DAViD-L di 10.73°. Model 5B menurunkan ini menjadi 6.73°, dan varian 4K mencapai 6.98° dengan median angular error hanya 3.08°.
Untuk albedo estimation, Sapiens2-5B mencapai MAE 0.012 dan PSNR 32.61 dB. Pada pointmap estimation, semua ukuran model Sapiens2 mengungguli MoGe yang sebelumnya state-of-the-art untuk monocular geometry estimation.
Yang paling menarik, dalam dense probing evaluations di mana backbone dibekukan dan hanya lightweight decoders yang dilatih, Sapiens2-5B mengungguli semua baseline termasuk DINOv3-7B (6.71B parameters). Padahal Sapiens2 adalah human-specialist model yang dievaluasi against general-purpose backbone hampir 1.5× lebih besar.
Praktikal takeaway untuk kamu yang kerja di computer vision atau content creation: kombinasi MAE dan contrastive learning dengan careful augmentation strategy bisa significantly improve representasi untuk task yang membutuhkan both semantic understanding dan appearance fidelity.
Kalau kamu develop model untuk human analysis, pertimbangkan untuk scale data curation dengan filtering pipeline yang systematic, dan jangan takut untuk combine multiple pretraining objectives yang complementary. Hasilnya bisa outperform general-purpose models yang jauh lebih besar.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

