Pelajari cara kerja knowledge distillation untuk mengompresi ensemble model AI menjadi satu model ringan yang tetap cerdas, lengkap dengan implementasi praktis menggunakan PyTorch.
Pernah bikin model AI yang akurasinya bagus banget, tapi pas mau deploy malah jadi masalah? Biasanya solusinya adalah ensemble — gabungin beberapa model biar hasilnya lebih akurat. Tapi ya, ensemble itu berat banget buat jalanin di production.
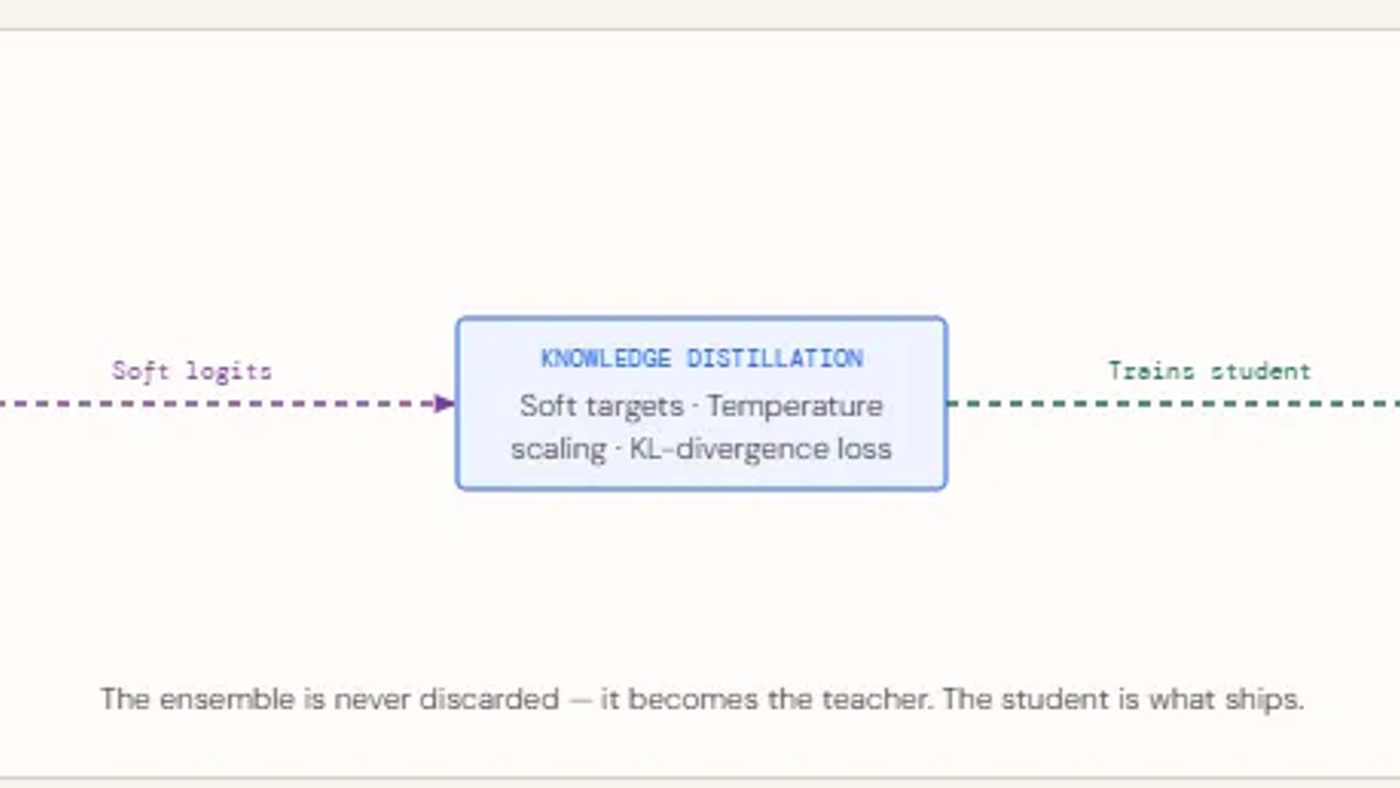
Nah, di sinilah knowledge distillation masuk. Intinya: daripada buang ensemble yang sudah susah-susah dibikin, kita pakai sebagai 'guru' buat ngajarin model kecil yang lebih ringan. Model kecil ini disebut 'student', dan dia belajar bukan cuma dari data asli, tapi juga dari cara guru memprediksi — termasuk seberapa yakin guru itu sama jawabannya.
Kenapa ini penting? Karena soft probability dari guru itu punya informasi lebih kaya daripada label keras 0 atau 1. Misalnya, kalau guru yakin 85% suatu gambar adalah kucing dan 15% anjing, student belajar bahwa kucing dan anjing itu mirip — bukan cuma 'ini kucing, end of story'.
Di artikel ini kita bakal lihat implementasi lengkapnya: mulai dari bikin 12 model teacher, generate soft targets pakai temperature scaling, sampai training student yang hasilnya bisa recover 53.8% keunggulan ensemble dengan kompresi 160 kali lipat.
Apa Itu Knowledge Distillation Secara Sederhana?
Knowledge distillation itu teknik kompresi model di mana model besar (teacher) transfer ilmunya ke model kecil (student). Student nggak cuma belajar dari ground-truth label, tapi juga mencoba meniru prediksi teacher — termasuk distribusi probabilitasnya.
Hasilnya? Student bisa mendekati performa model kompleks tapi tetap jauh lebih kecil dan cepat. Teknik ini awalnya buat nge-compress ensemble, sekarang dipakai di NLP, computer vision, sampai generative AI buat bikin model besar jadi deployable.
Setup dan Persiapan Data
Pertama kita butuh PyTorch dan scikit-learn. Dataset yang dipakai adalah synthetic classification dengan 5000 sampel dan 20 fitur — mirip kasus prediksi klik iklan atau churn user.
Data di-split jadi train-test, kemudian di-standardize pakai StandardScaler. Ini penting biar neural network training-nya lebih stabil. Terakhir, data dikonversi ke tensor PyTorch dan dibungkus dalam DataLoader dengan batch size 64.
Arsitektur Model: Teacher vs Student
TeacherModel punya 4 layer dengan width yang lebar: 256 → 128 → 64 → output. Ada dropout 0.3 buat regularisasi. Ini representasi satu model di dalam ensemble — expressive tapi komputasinya mahal.
StudentModel jauh lebih ramping: cuma 2 hidden layer 64 → 32. Tapi jangan salah, kapasitas ini cukup buat nangkep knowledge yang di-distill. Yang penting bukan sekecil mungkin, tapi sekecil mungkin yang masih bisa belajar pola dari teacher.
Training Ensemble 12 Model
Di sini kita train 12 teacher model secara independen, masing-masing dengan random initialization berbeda. Keanekaragaman inilah yang bikin ensemble kuat — tiap model belajar pola sedikit berbeda dari data yang sama.
Setelah training 30 epoch per model, prediksi mereka digabung pakai soft voting: rata-ratain logits-nya, bukan cuma majority vote. Hasilnya ensemble dengan akurasi 97.80% — ini yang jadi target kita buat student.
Generate Soft Targets dengan Temperature Scaling
Ini bagian kunci dari distillation. Soft targets dibuat dengan ngerata-ratain logits dari 12 teacher, terus di-scale pakai temperature T=3.0. Temperature tinggi bikin distribusi lebih 'lembut', jadi student bisa lihat hubungan antar kelas yang lebih subtle.
Contohnya: kalau hard label cuma bilang 'kelas 0', soft target bisa jadi [0.72, 0.28] — artinya guru agak yakin ini kelas 0, tapi ada kemungkinan kecil kelas 1. Informasi tambahan ini yang bikin student belajar lebih baik.
Training Student via Knowledge Distillation
Student dilatih dengan dua loss sekaligus. Pertama, distillation loss pakai KL-divergence buat cocokin distribusi student dengan soft target dari teacher. Kedua, hard label loss pakai cross-entropy biasa buat tetap align sama ground truth.
Kedua loss di-weight dengan ALPHA=0.7 — artinya 70% fokus ke soft target, 30% ke hard label. Temperature scaling dipakai lagi buat konsistensi, dengan rescaling factor T² biar gradient-nya stabil. Training berjalan 50 epoch.
Baseline: Student Tanpa Distillation
Buat fair comparison, kita juga train student identik tapi cuma pakai hard label. Arsitektur sama, data sama, training process sama — bedanya cuma nggak ada guidance dari ensemble. Ini jadi benchmark buat ukur seberapa besar benefit dari distillation.
Hasilnya? Baseline student dapet akurasi 96.50% — nggak buruk, tapi kita lihat seberapa jauh distillation bisa bawa ini ke level berikutnya.
Perbandingan Hasil: Siapa yang Menang?
Ensemble 12 model: 97.80% — ini ceiling-nya, tapi nggak feasible buat production. Baseline student: 96.50% — acceptable tapi ada gap 1.3% dari ensemble. Distilled student: 97.20% — hanya 0.6% di bawah ensemble!
Gap 0.70% antara baseline dan distilled student itu bukan kebetulan — itu nilai measurable dari soft targets. Student nggak dapet data lebih, arsitektur lebih bagus, atau komputasi lebih. Cuma sinyal training yang lebih kaya, dan itu recover 53.8% dari gap yang tadinya ada.
Sisa gap 0.60% ke ensemble adalah 'honest cost of compression' — bagian dari knowledge ensemble yang simply nggak bisa ditampung model 3,490 parameter, regardless seberapa bagus training-nya.
Takeaway Praktis buat Kamu
Kalau kamu punya ensemble yang akurat tapi terlalu berat buat deploy, jangan langsung buang. Knowledge distillation bisa jadi jalan tengah yang ideal — model tetap ringan tapi performanya mendekati yang berat.
Yang perlu diperhatikan: pilih temperature yang sesuai (biasanya 2-5), balance alpha antara distillation dan hard label loss, dan pastikan student punya kapasitas cukup buat nangkep knowledge dari teacher.
Di contoh ini, kompresi 160x dengan recovery 53.8% knowledge itu trade-off yang worth it buat banyak use case production. Kamu bisa coba implementasi serupa di project AI-mu sendiri!
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→