Pelajari kenapa LoRA standar gagal menangkap pengetahuan kompleks saat fine-tuning LLM dan bagaimana RS-LoRA dengan scaling √r mengatasi masalah ini.
LoRA jadi pilihan populer buat fine-tuning model besar karena hemat resource. Tapi ada asumsi diam-diam yang sering dilewatin: LoRA nganggap semua update ke model itu mirip-mirip.
Nyatanya? Nggak gitu. Beda tujuan fine-tuning, beda juga karakter update-nya.
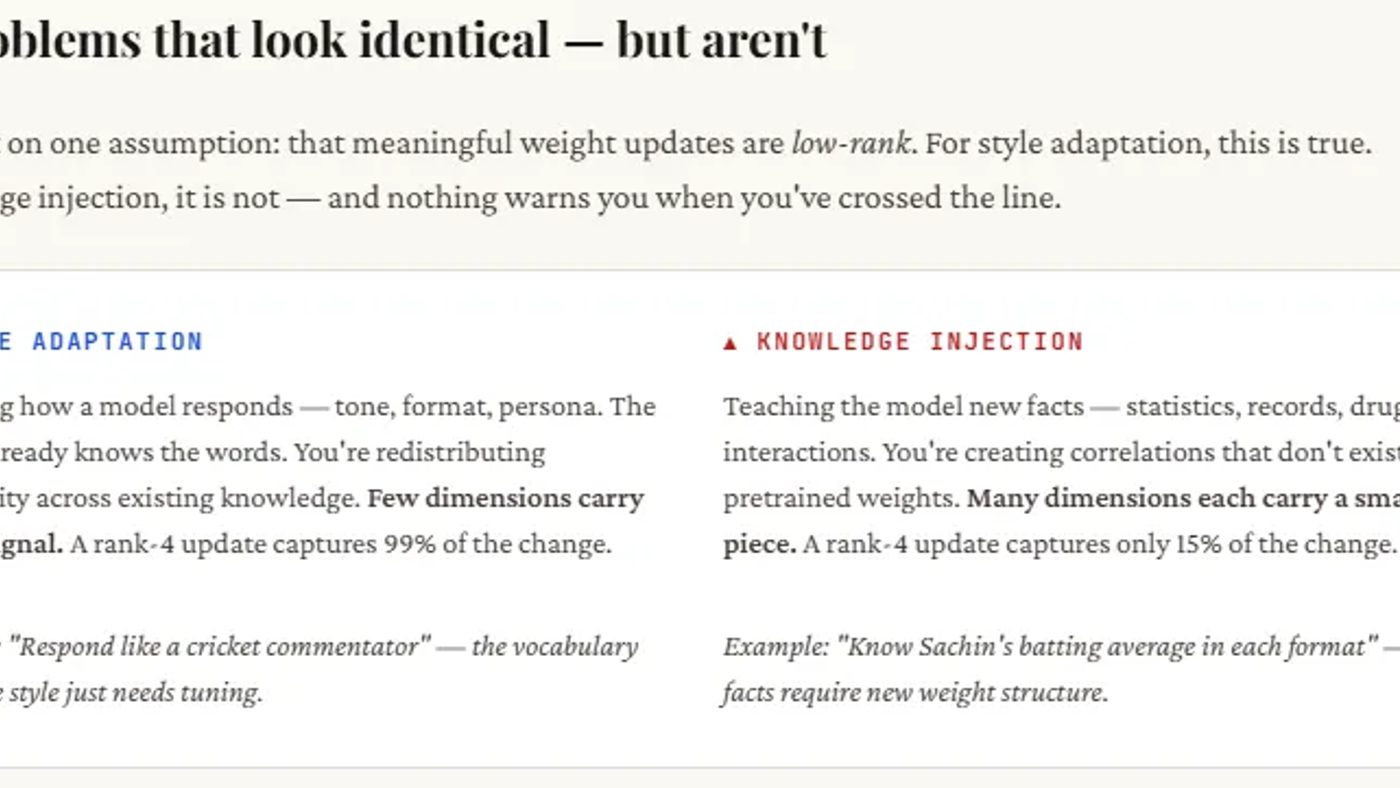
Kalau kamu fine-tune buat gaya — kayak tone, format, atau persona — perubahannya simpel dan terkonsentrasi di beberapa dimensi aja. LoRA dengan rank rendah nangkep ini dengan baik.
Tapi kalau kamu mau ngajarin model fakta baru — data medis, statistik, domain knowledge — informasinya tersebar di banyak dimensi. Rank-8? Nggak cukup. Model bisa kedengaran bener tapi jawabannya salah atau nggak lengkap.
Solusi intuitif: naikin rank. Tapi ini malah bikin masalah baru.
Pas rank dinaikin, scaling standar LoRA (alpha dibagi r) bikin sinyal pembelajaran melemah. Training jadi nggak efektif.
Di sinilah RS-LoRA masuk. Cuma ganti rumus scaling: dari bagi r jadi bagi √r. Perubahan kecil yang nge-stabilin learning meski rank tinggi.
Simulasi berikut nunjukin kegagalan ini dari first principles pakai NumPy. Nggak ada training loop, nggak ada framework — cuma matematika murni.
Kita simulasi dua tipe update: style (low-rank) dan facts (high-rank). Terus ukur berapa informasi yang selamat di tiap rank.
Hasilnya? Style update dengan singular values yang cepat turun — rank 4 udah nangkep 99%+ informasi. Facts update? Singular values turun pelan, rank 8 cuma nangkep ~28%.
Ini yang disebut "long tail problem": tiap dimensi tambahan tetap penting. LoRA yang motong ke rank rendah motong ekor ini, bikin pengetahuan jadi tidak lengkap.
Masalah kedua: scaling collapse. Standard LoRA dengan alpha/r, pas rank naik dari 1 ke 64, scaling-nya anjlok dari 16 jadi 0.25. Update jadi terlalu lemah.
RS-LoRA dengan alpha/√r? Scaling turun lebih pelan — di rank 64 masih 2.0. Cukup kuat buat manfaatin representasi high-rank tanpa bunuh sinyal.
Intinya: LoRA standar nambah kapasitas tapi bunuh impact-nya. RS-LoRA nyimpen keduanya.
Praktisnya gimana? Kalau fine-tuning kamu fokus gaya atau instruksi sederhana, LoRA standar dengan rank 4-8 cukup. Tapi kalau butuh factual knowledge yang kompleks — medis, hukum, teknik — pertimbangkan RS-LoRA dengan rank lebih tinggi.
Cek juga reconstruction error di eksperimenmu. Kalau error tinggi meski rank udah dinaikin, itu tanda LoRA standar lagi struggle dan RS-LoRA bisa jadi solusi.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

