xAI rilis grok-voice-think-fast-1.0, model AI suara yang mengungguli Gemini dan GPT Realtime di benchmark τ-voice. Sudah dipakai Starlink dengan hasil nyata.
Membangun AI suara yang benar-benar bisa dipakai di produksi itu susah banget, lho. Bukan cuma soal transkripsi yang akurat, tapi sistemnya harus bisa ingat konteks percakapan lima menit, panggil API di tengah-tengah telepon tanpa jeda canggung, dan tetap kerja meski ada noise atau aksen berat.
Kebanyakan sistem sekarang cuma bisa handle satu-dua dari itu. Nah, xAI baru aja rilis grok-voice-think-fast-1.0 yang klaimnya bisa handle semuanya — dan angka benchmark-nya memang mendukung.
Model ini tersedia lewat xAI API dan sudah dipakai secara live untuk operasi telepon Starlink. Jadi ini bukan cuma teori, tapi udah battle-tested di lapangan.
Apa sih yang bikin voice agent ini beda? grok-voice-think-fast-1.0 itu full-duplex, artinya dia dengerin dan ngomong secara bersamaan kayak manusia beneran. Dia nggak nunggu kamu selesai baru mikir.
Ini yang bikin handle interruption itu technically challenging. Model harus real-time nentuin: ini yang ngomorin koreksi, klarifikasi, atau cuma filler word? Terus adjust behavior-nya.
Benchmark τ-voice itu nge-test kondisi realistis: noise, aksen, interruption, dan turn-taking alami. Jauh lebih relevan buat produksi daripada benchmark ASR audio bersih tradisional.
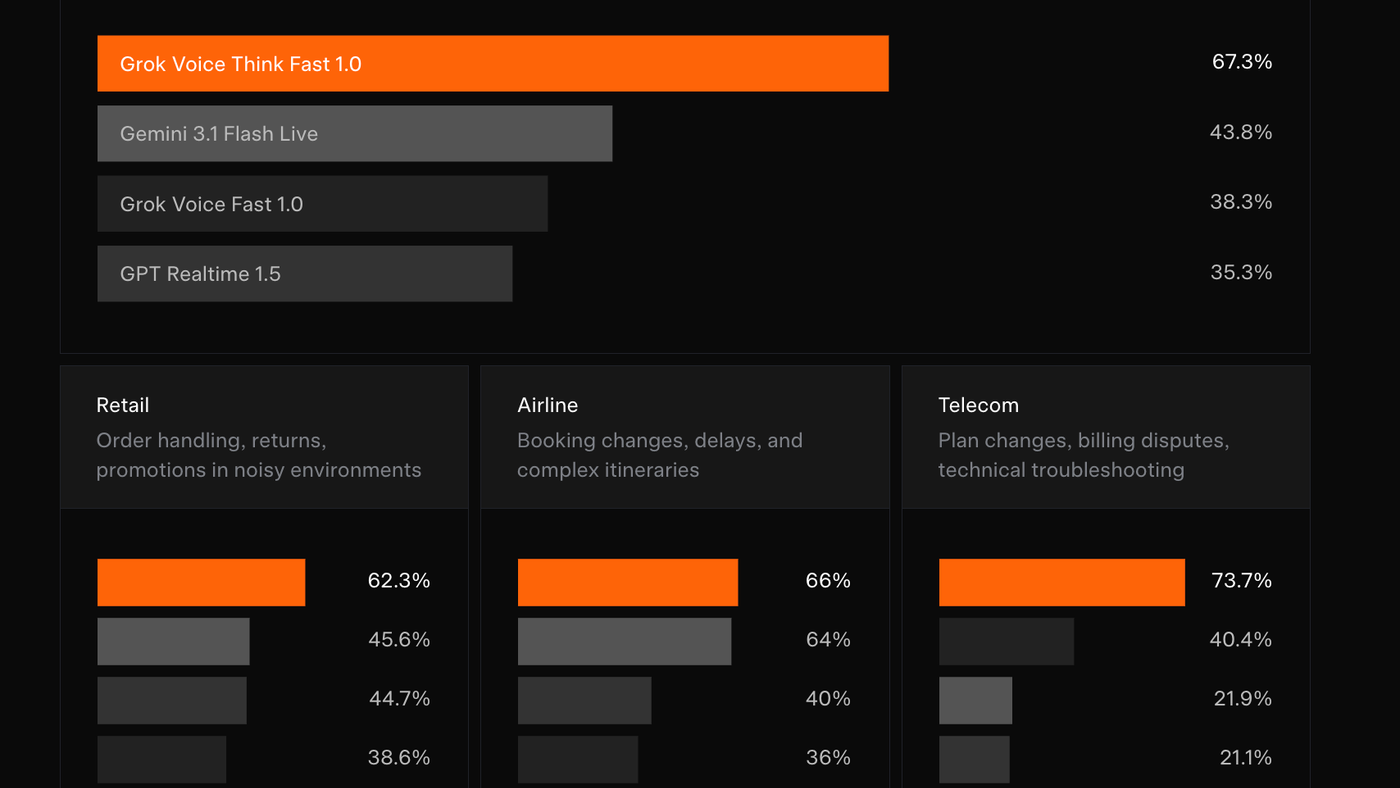
Hasil benchmark-nya? Gokil. grok-voice-think-fast-1.0 dapet 67.3% di τ-voice Bench overall. Bandingin sama Gemini 3.1 Flash Live (43.8%), Grok Voice Fast 1.0 versi lama (38.3%), dan GPT Realtime 1.5 (35.3%).
Kalau dibreakdown per industri, bedanya makin kelihatan. Di Retail — handle order, return, promo di environment berisik — skornya 62.3%. Pesaing terdekat baru 44-45%.
Di Airline — booking changes, delay, itinerary kompleks — grok-voice-think-fast-1.0 dapet 66%. Gemini cuma 40%, GPT Realtime 36%.
Yang paling dramatis di Telecom: plan changes, billing dispute, troubleshooting teknis. grok-voice-think-fast-1.0 dapet 73.7%. Pesaing terdekat cuma 40%, yang lain di bawah 22%. Selisih 33 percentage point itu bukan improvement kecil, tapi architectural advantage.
Satu hal yang technically impressive: reasoning-nya jalan di background dengan zero added latency. Biasanya model reasoning itu bikin response lambat karena harus generate 'thinking tokens' dulu.
xAI berhasil sembunyiin komputasi itu dari latency budget percakapan. Jadi kamu dapet accuracy tanpa sluggishness. Contohnya: ditanya 'bulan apa yang ada huruf X?' grok-voice-think-fast-1.0 bener jawab 'nggak ada'. Model lain dengan percaya diri salah jawab 'February'.
Error model yang kedengaran plausible tapi salah itu bahaya banget di voice interface. Soalnya user nggak ada teks buat cross-check.
Fitur keren lain: precise data entry dan read-back. Model bisa capture email, alamat, nomor telepon, nama, account number — meski ngomongnya cepet, aksen berat, atau ada correction di tengah.
Contoh konkret: caller ngomong 'Yep, it's 1410, uh wait, 1450 Page Mill Street. Actually no sorry, that's Page Mill Road.' Model proses koreksi real-time, invoke search_address tool dengan parameter yang bener, terus read-back buat konfirmasi.
Buat data teams yang biasa build post-call cleanup pipeline, capability ini ngurangin complexity downstream processing secara signifikan.
Model ini udah di-test di kondisi paling berat: audio telepon, background noise, aksen berat, interruption terus-menerus. Support 25+ bahasa, cocok buat deployment global.
Validasi paling kuat bukan benchmark, tapi deployment live-nya. Grok Voice powers full phone sales dan customer support Starlink di +1 (888) GO STARLINK.
Angka dari deployment ini operationally significant: 20% sales conversion rate (satu dari lima caller yang inquiry sales jadi beli Starlink sambil telepon), 70% autonomous resolution rate untuk customer support tanpa human in the loop.
Satu agent operasi across 28 distinct tools, spanning ratusan workflow support dan sales. Ini bukti production readiness at scale.
Practical takeaway buat kamu yang kerja di AI atau product: voice AI yang beneran production-grade itu butuh full-duplex architecture, background reasoning tanpa latency penalty, dan native structured data capture. Benchmark clean audio itu misleading, fokus ke realistic condition testing.
Kalau kamu lagi evaluate voice AI untuk customer support atau sales, τ-voice Bench lebih relevan daripada ASR benchmark tradisional. Dan grok-voice-think-fast-1.0 setidaknya worth dicoba berdasarkan angka dan deployment proof-nya.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

