GPT-5.5 adalah model agentic terbaru OpenAI yang bisa coding, browsing, dan mengoperasikan software tanpa supervisi manusia. Pelajari benchmark, harga, dan cara kerjanya.
OpenAI baru saja merilis GPT-5.5, dan ini bukan sekadar update kecil. Ini adalah model base yang sepenuhnya dilatih ulang pertama sejak GPT-4.5, dengan fokus utama pada kemampuan agentic.
Bedanya apa? GPT-5.5 dirancang untuk menyelesaikan tugas komputer multi-step dengan arahan minimal dari manusia. Kalau model sebelumnya masih butuh checklist terus-menerus, yang ini paham tujuan besar dan bisa menyusun langkah-langkahnya sendiri.
Rilis ini sudah tersedia hari ini untuk subscriber Plus, Pro, Business, dan Enterprise di ChatGPT dan Codex.
Apa sih "agentic" itu sebenarnya? Model agentic tidak cuma membalas satu prompt lalu berhenti.
Dia mengambil serangkaian tindakan, pakai tools seperti browsing web, menulis kode, menjalankan script, atau mengoperasikan software. Dia juga bisa cek hasil kerjanya sendiri dan lanjut sampai tugas selesai.
Model-model sebelumnya sering macet di titik handoff, butuh user untuk re-prompt atau koreksi. GPT-5.5 dibuat untuk mengurangi interupsi semacam itu.
Empat area ini jadi fokus utama: agentic coding, computer use, knowledge work, dan riset ilmiah awal. OpenAI bilang ini domain "di mana kemajuan bergantung pada reasoning lintas konteks dan tindakan dari waktu ke waktu."
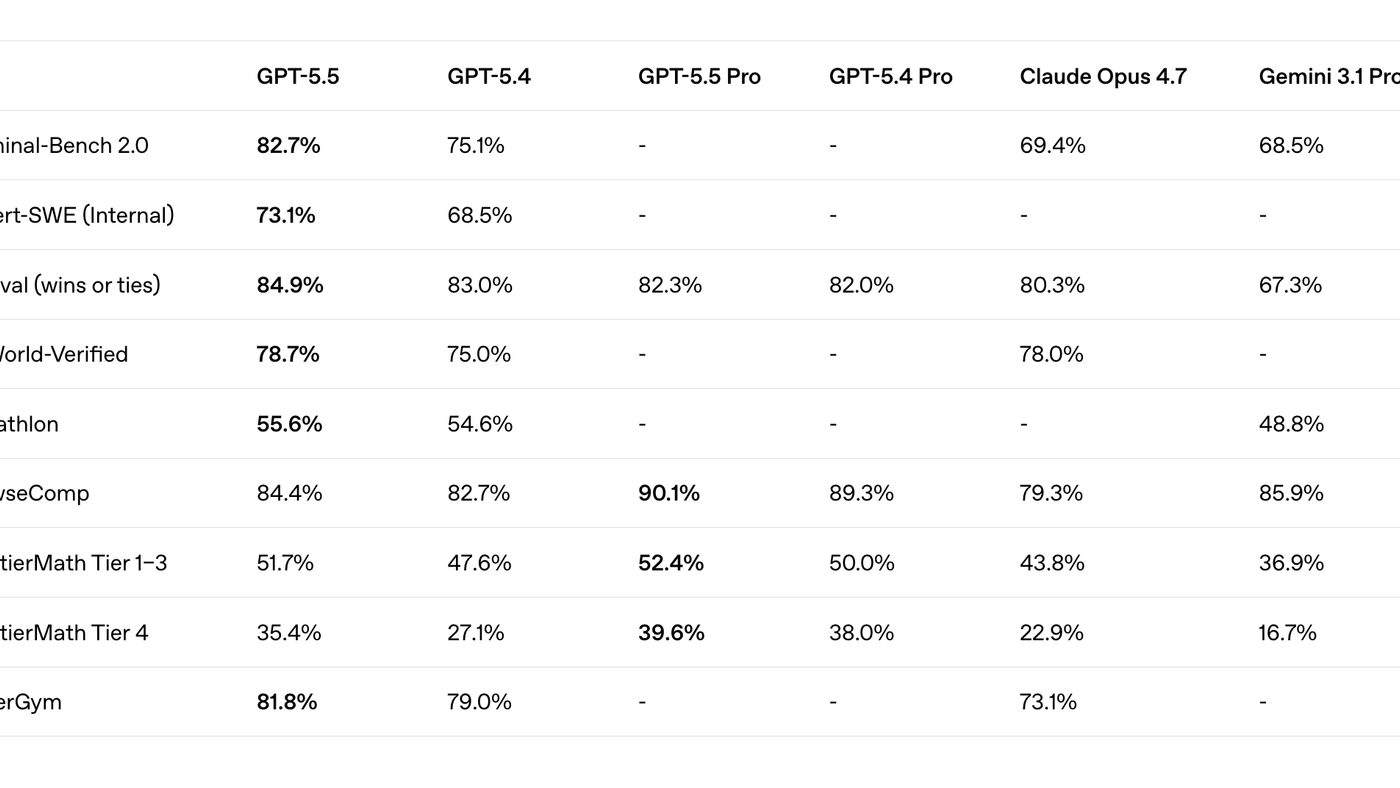
Untuk software engineer, benchmark paling relevan adalah SWE-Bench Pro. GPT-5.5 menyelesaikan 58.6% tugas end-to-end dalam satu pass.
Catatan penting: Claude Opus 4.7 memang lebih tinggi di 64.3%, tapi OpenAI menyebut ada indikasi memorization di subset masalah tersebut yang bisa memengaruhi perbandingan.
Untuk coding jangka panjang, ada Expert-SWE, benchmark internal OpenAI dengan median waktu penyelesaian manusia 20 jam. GPT-5.5 mengungguli GPT-5.4 di sini.
Ini penting karena merepresentasikan kerja engineering multi-sesi: refactor besar, build fitur, debugging di dalam codebase. Developer yang tes awal bilang GPT-5.5 lebih paham "bentuk" sistem software dan bisa mengerti kenapa sesuatu gagal, di mana perlu fix, dan apa dampaknya ke bagian lain codebase.
Untuk ML engineer dan data scientist yang sering di terminal, Terminal-Bench 2.0 adalah sinyal paling menarik. GPT-5.5 skor 82.7%, mengungguli Claude Opus 4.7 (69.4%) dan Gemini 3.1 Pro (68.5%).
Ini bukan lead tipis-tipis. Benchmark ini menguji workflow command-line kompleks yang butuh planning, iterasi, dan koordinasi tools.
Untuk knowledge work secara luas, GPT-5.5 skor 84.9% di GDPval yang menguji agent di 44 profesi kerja pengetahuan. Di OSWorld-Verified, benchmark operasi komputer mandiri, dia mencapai 78.7%.
Ada juga varian Pro untuk tugas dengan akurasi lebih tinggi. GPT-5.5 Pro skor 90.1% di BrowseComp, kemampuan tracking informasi sulit di web, mengungguli Gemini 3.1 Pro (85.9%).
Model ini juga ranking pertama di Artificial Analysis Intelligence Index.
Kecepatan dan efisiensi token jadi perhatian. Model yang lebih capable biasanya lebih lambat atau mahal.
OpenAI mengklaim GPT-5.5 match latency per-token GPT-5.4 di serving real-world, tapi performa lebih baik di hampir semua evaluasi. Dia juga pakai token jauh lebih sedikit untuk tugas Codex yang sama.
Harga API naik: $5 per juta input tokens dan $30 per juta output tokens, dari $2.50 dan $15 untuk GPT-5.4. Varian Pro lebih mahal lagi: $30 input dan $180 output per juta tokens.
Tapi tim OpenAI bilang efisiensi token meng-offset kenaikan harga. Kalau GPT-5.5 selesaikan tugas dengan token jauh lebih sedikit, cost per workflow yang selesai bisa tetap lebih murah meski rate per-token lebih tinggi.
Untuk tim yang jalanin Codex dalam skala besar, perhitungan net yang penting: efektivitas biaya per tugas selesai, bukan harga per token.
OpenAI melihat lonjakan penggunaan Codex, dengan sekitar 4 juta developer pakai tool ini tiap minggu. GPT-5.5 bukan research preview tapi model produksi yang langsung didorong ke base developer aktif dan besar.
Praktisnya, apa yang bisa kamu ambil? Kalau kamu developer, data scientist, atau knowledge worker, GPT-5.5 bisa jadi asisten yang benar-benar mandiri untuk tugas-tugas kompleks.
Mulai dari menulis dan debug kode, browsing informasi, mengisi spreadsheet, sampai operasi software — semua bisa berjalan dengan supervisi minimal. Efisiensi token yang lebih baik juga berarti workflow agentic yang lebih cepat dan potensial lebih murah dalam jangka panjang, meski harga per token naik.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

