Decoupled DiLoCo dari Google DeepMind mengubah cara training model AI besar dengan arsitektur asynchronous yang tahan hardware failure dan hemat bandwidth.
Training model AI skala besar itu sebenarnya masalah koordinasi. Ribuan chip harus komunikasi terus-menerus, sinkron setiap gradient update. Kalau satu chip aja lemot atau mati, seluruh proses training bisa berhenti total.
Nah, Google DeepMind punya solusi baru namanya Decoupled DiLoCo. Sistem ini memecah training jadi beberapa 'pulau' komputasi yang jalan asynchronous, jadi nggak perlu sinkronisasi ketat kayak metode tradisional.
Kenapa metode lama bermasalah? Data-Parallel training standar itu replika model di banyak accelerator. Setiap forward dan backward pass, gradient harus di-average via AllReduce. Ini blocking step, artinya semua device nunggu yang paling lambat.
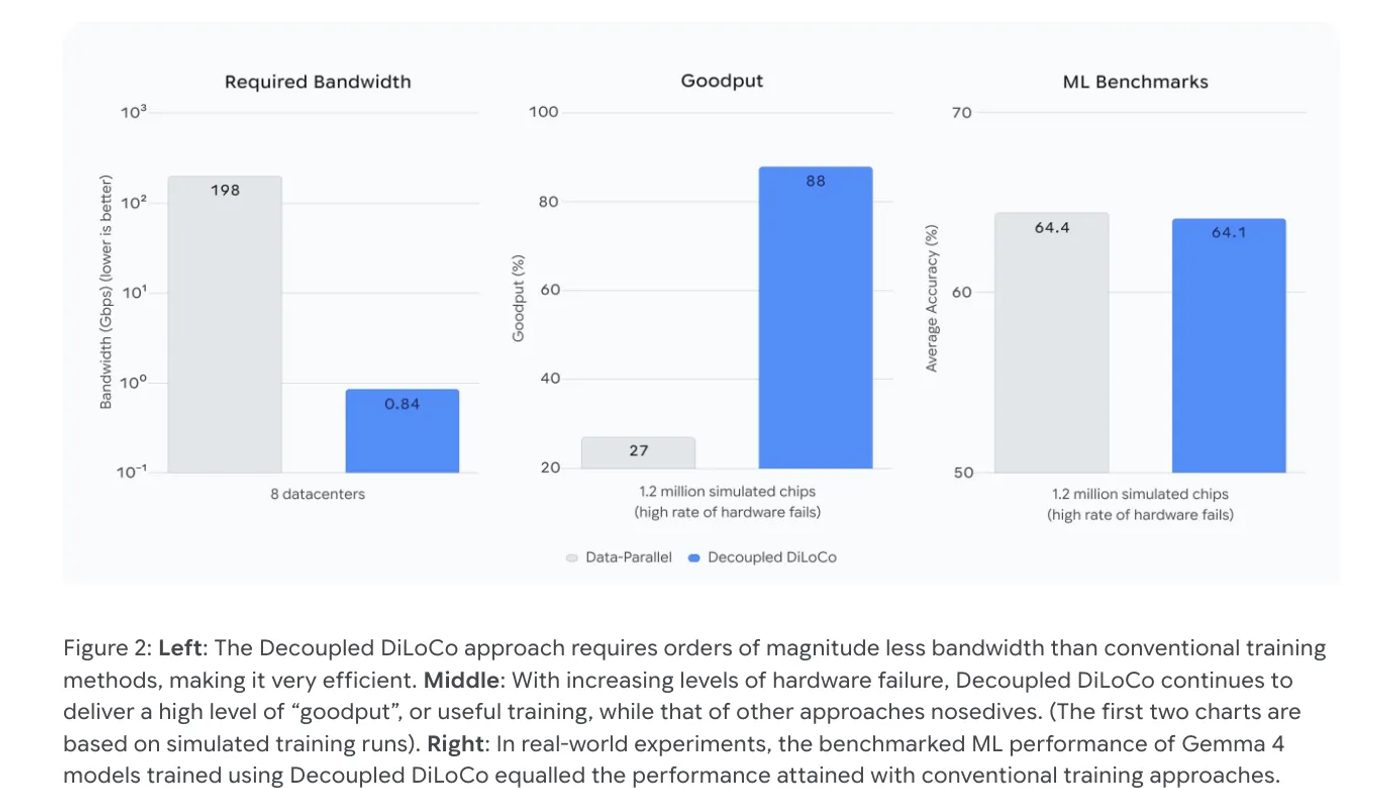
Bayangin ribuan chip di beberapa data center. Satu yang lemot = semua stuck. Plus butuh bandwidth ~198 Gbps antar data center, jauh di atas kapasitas WAN standar.
Decoupled DiLoCo kombinasi dua teknologi Google sebelumnya: Pathways dan DiLoCo. Pathways pakai asynchronous data flow, tiap resource kerja sesuai pace-nya sendiri. DiLoCo bikin tiap worker jalan banyak local steps dulu sebelum komunikasi.
Hasilnya? Training dibagi ke learner units yang semi-independen. Tiap unit jalan local steps banyak, baru share compressed gradient ke outer optimizer. Karena asynchronous, satu island yang fail nggak bikin yang lain berhenti.
Penghematan bandwidth-nya gila: dari 198 Gbps turun ke 0.84 Gbps. Beda beberapa order of magnitude. Jadi cukup pakai koneksi internet standar antar data center, nggak perlu infrastruktur khusus super mahal.
Tim riset pakai chaos engineering buat test: sengaja bikin hardware failure artificial. Sistem tetap training meski kehilangan entire learner units, terus seamless reintegrasi pas unit balik online. Ini yang mereka sebut 'self-healing'.
Di simulasi 1.2 juta chip dengan failure rate tinggi, Decoupled DiLoCo maintain goodput 88%. Data-Parallel standar? Cuma 27%. Goodput ini penting soalnya training dengan compute tinggi tapi goodput rendah itu buang resource.
Yang keren: resilience ini nggak bikin kualitas model turun. Pakai Gemma 4, accuracy 64.1% vs baseline 64.4%. Bedanya dalam noise variance evaluasi biasa.
Tim juga validasi production scale: training model 12B parameter across 4 region di AS, pakai bandwidth 2-5 Gbps doang. Ini 20x lebih cepat dari metode sinkronisasi konvensional.
Rahasianya: komunikasi di-fold ke dalam periode komputasi yang lebih panjang, bukan jadi blocking step. Jadi nggak ada yang nunggu-nunggu.
Satu fitur underrated: support heterogeneous hardware. Learner units jalan asynchronous, jadi nggak perlu hardware identikal dengan clock speed sama.
Tim demo training pakai mix TPU v6e dan TPU v5p dalam satu job, tanpa degradasi performance. Ini praktis banget: extend useful life hardware lama, plus alleviate bottleneck pas transisi hardware generation.
Practical takeaway buat kamu yang kerja di ML infrastructure: desain sistem asynchronous dan fault-isolated itu game-changer. Jangan bikin arsitektur yang perfect-world assumption, soalnya hardware failure itu bukan exception tapi norma di scale besar.
Kalau kamu lagi bangun training pipeline, pertimbangkan: bisa nggak komponen jalan semi-independen? Bisa nggak graceful degradation pas ada failure? Bisa nggak mix hardware generations? Decoupled DiLoCo nunjukin ini semua achievable dengan tradeoff minimal.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

