Claude Opus 4.7 hadir dengan upgrade besar untuk coding otonom, visi resolusi tinggi 3.75 megapiksel, dan fitur baru seperti xhigh effort level serta /ultrareview di Claude Code.
Anthropic baru saja merilis Claude Opus 4.7, model frontier terbaru mereka yang jadi penerus langsung Opus 4.6.
Meski bukan lompatan generasi penuh, upgrade ini bawa peningkatan substansial di area yang paling dibutuhkan developer: software engineering otonom, reasoning multimodal, dan eksekusi tugas mandiri yang berjalan lama.
Opus 4.7 duduk di puncak keluarga model Claude — di atas Haiku dan Sonnet, tapi masih di bawah Claude Mythos yang masih dalam rilis terbatas.
Yang menarik, model ini bisa handle tugas coding tersulit yang sebelumnya butuh supervisi ketat.
Kamu bisa serahkan pekerjaan kompleks dan berjalan lama ke Opus 4.7 dengan percaya diri — dia bakal perhatikan instruksi dengan presisi, terus konsisten, dan bahkan nemuin cara buat verifikasi output-nya sendiri sebelum lapor balik.
Perilaku self-verification ini beda banget dari model-model sebelumnya yang sering output hasil tanpa sanity check internal.
Implikasinya besar buat CI/CD pipelines dan agentic workflows multi-step.
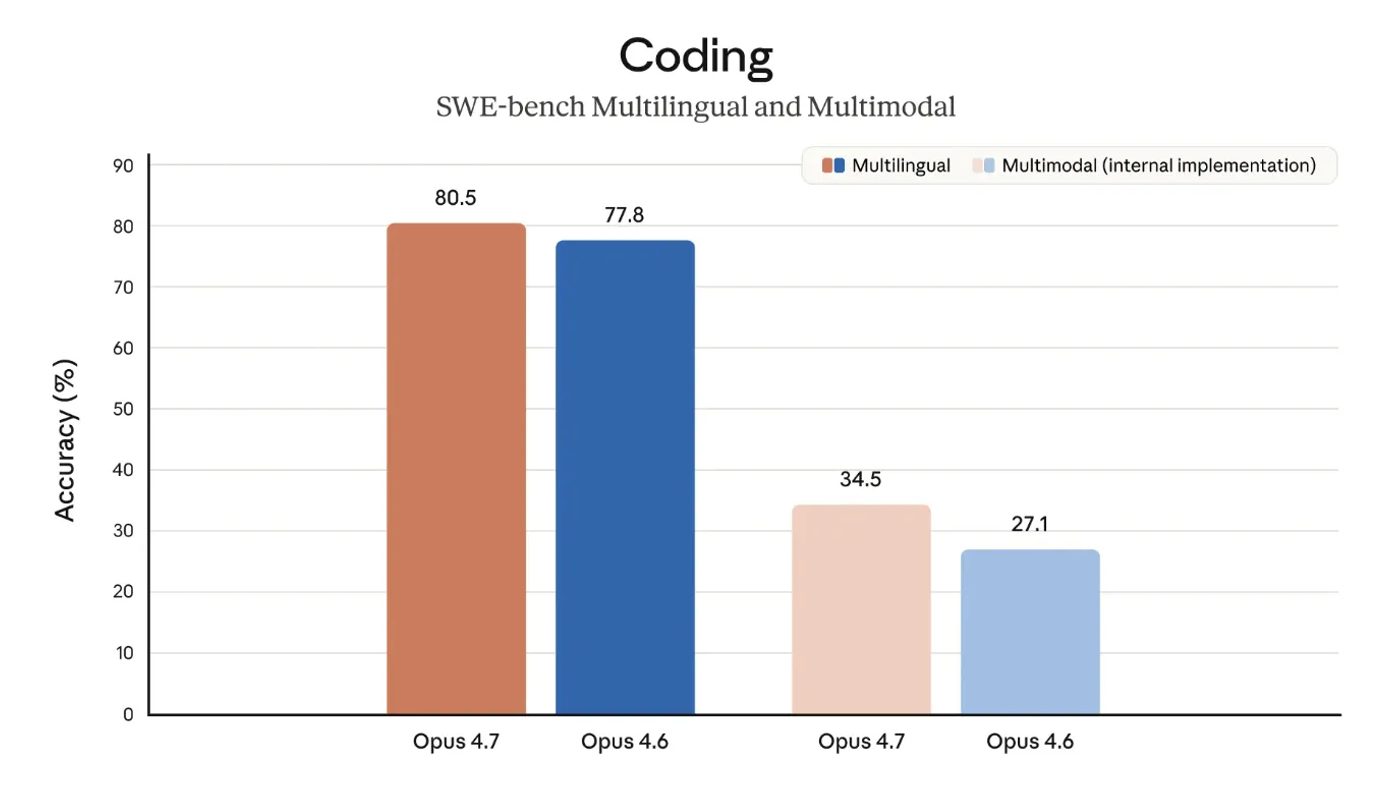
Di benchmark coding 93 tugas, Opus 4.7 naik 13% dari Opus 4.6 — termasuk 4 tugas yang sama sekali nggak bisa diselesaikan Opus 4.6 atau Sonnet 4.6.
Di CursorBench yang populer di kalangan developer, skornya melonjak dari 58% jadi 70%.
Satu tester bahkan catat peningkatan 14% untuk workflow multi-step kompleks, dengan token lebih sedikit dan error tool cuma sepertiga dari sebelumnya.
Opus 4.7 juga jadi model pertama yang lolos implicit-need tests mereka — dia terus eksekusi meski ada tool failure yang dulu bakal stop Opus 4.6.
Satu upgrade teknis yang konkret: kemampuan visual Opus 4.7 sekarang bisa terima gambar sampai 2.576 piksel di sisi terpanjang, atau sekitar 3.75 megapiksel.
Itu lebih dari 3x resolusi dari model Claude sebelumnya.
Banyak aplikasi dunia nyata — dari computer-use agents yang baca screenshot UI padat sampai ekstraksi data dari diagram engineering kompleks — gagal bukan karena model nggak bisa reasoning, tapi karena nggak bisa resolve detail visual yang halus.
Satu tester yang kerja di computer-use workflows lapor Opus 4.7 dapet skor 98.5% di benchmark visual-acuity mereka, bandingkan dengan 54.5% untuk Opus 4.6.
Ini perubahan di level model, bukan parameter API — jadi gambar yang kamu kirim ke Claude bakal diproses dengan fidelity lebih tinggi secara otomatis.
Cuma ingat, gambar resolusi tinggi konsumsi token lebih banyak, jadi kalau detail ekstra nggak dibutuhkan, kamu bisa downsample dulu sebelum kirim.
Buat developer yang pakai Claude API, ada dua kontrol baru buat atur compute spend.
Pertama, effort level baru namanya xhigh (extra high) yang ada di antara high dan max — kasih kontrol lebih halus buat tradeoff antara reasoning dan latency di masalah sulit.
Di Claude Code, tim Anthropic udah naikin default effort level jadi xhigh untuk semua plan.
Kedua, task budgets sekarang launching public beta di Claude Platform API — kasih developer cara buat guide token spend Claude supaya bisa prioritize kerjaan di run yang lebih panjang.
Dua kontrol ini sangat relevan kalau kamu jalanin parallelized agent pipelines di production, di mana cost per-call dan latency harus dikelola dengan hati-hati.
Ada dua fitur baru di Claude Code yang rilis bareng Opus 4.7.
Slash command /ultrareview bikin sesi review khusus yang baca perubahan dan flag bug serta design issues yang reviewer teliti bakal tangkep.
Anthropic kasih user Pro dan Max tiga ultrareview gratis buat coba.
Bayangin aja punya senior engineer yang bisa review kode on demand — berguna banget sebelum merge PR kompleks atau deploy ke production.
Terus, auto mode sekarang juga available buat Max users.
Di mode ini, Claude bisa ambil keputusan atas nama kamu — artinya tugas panjang bisa jalan dengan interupsi lebih sedikit, tapi risikonya lebih kecil daripada kalau kamu pilih skip semua permissions.
Ini sangat valuable buat agents yang eksekusi tugas multi-step semalaman atau di codebase besar.
Satu improvement yang kurang dibahas tapi signifikan secara operasional: cara Opus 4.7 handle memory.
Model ini lebih jago pakai file system-based memory — dia ingat catatan penting di kerjaan multi-session yang panjang dan pake itu buat lanjut tugas baru yang jadi butuh konteks awal lebih sedikit.
Di benchmark pihak ketiga, Opus 4.7 juga dapet hasil state-of-the-art di GDPval-AA — evaluasi knowledge work bernilai ekonomi tinggi di bidang finance, legal, dan domain lain.
Praktisnya, kalau kamu developer yang build AI-powered applications, Opus 4.7 bisa jadi game-changer buat workflow coding otonom.
Mulai dari effort level xhigh buat masalah sulit, manfaatin task budgets buat kontrol cost di pipeline production, sampai coba /ultrareview sebelum merge kode penting.
Dan kalau kerjaan kamu bergantung pada detail visual — mulai dari parsing diagram sampai computer-use agents — upgrade visi 3x ini bakal eliminate pain point besar yang selama ini ada.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→![A Report on Burnout in Open Source Software Communities (2025) [pdf]](https://cdn.sanity.io/images/dc330kkz/production/5abef2280c91c15bf2815dd8fd0ec564c6d1c72d-1024x576.jpg?w=1400&h=788&fit=crop&auto=format&q=82)

