Alibaba meluncurkan Qwen3.6-27B, model AI dense 27 miliar parameter yang mengalahkan MoE 397B di benchmark coding. Pelajari fitur Thinking Preservation dan arsitektur hybrid Gated DeltaNet-nya.
Tim Qwen dari Alibaba baru saja merilis Qwen3.6-27B. Ini adalah model dense open-weight pertama di keluarga Qwen3.6, dan bisa dibilang model 27B paling capable yang tersedia buat coding agents saat ini.
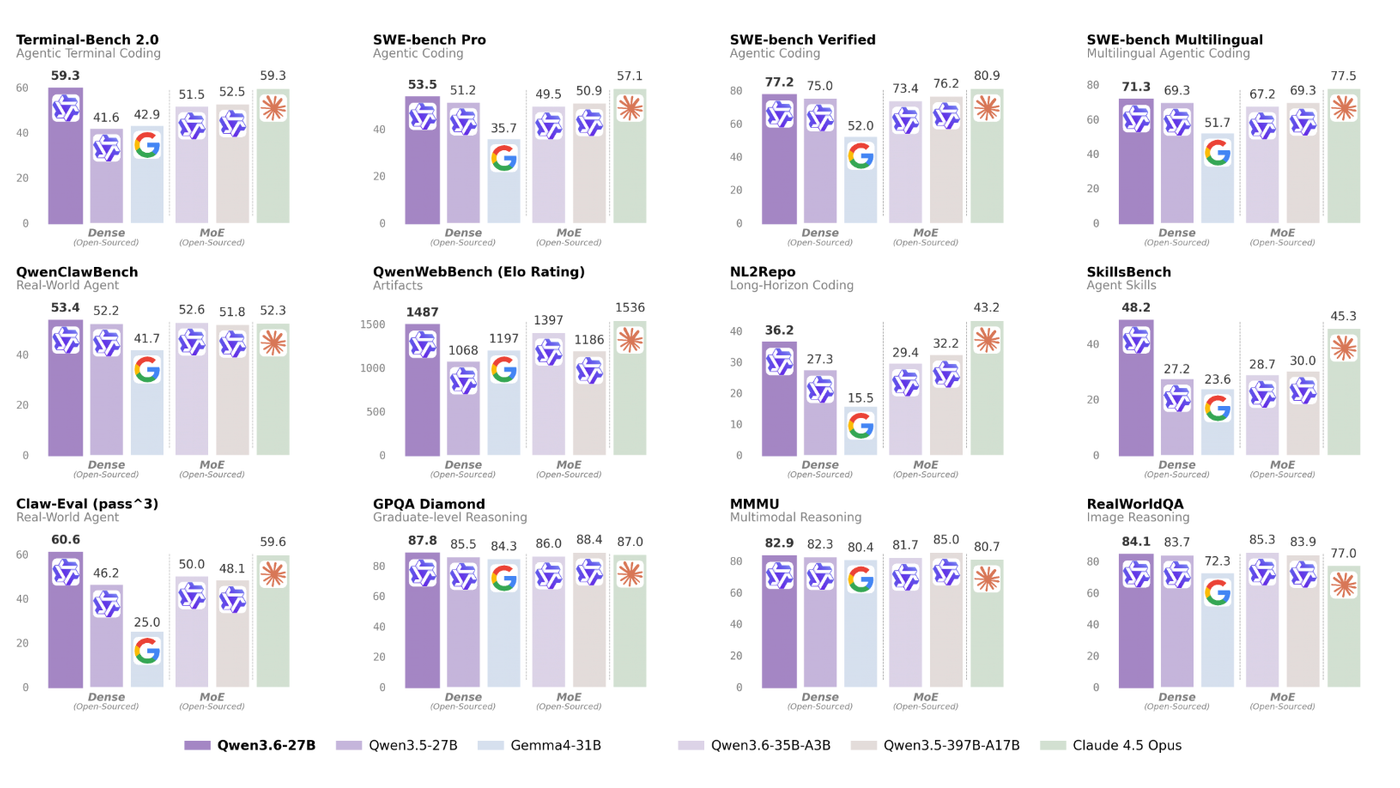
Yang menarik, model ini justru mengalahkan Qwen3.6-35B-A3B dan bahkan Qwen3.5-397B-A17B yang jauh lebih besar di beberapa benchmark agentic coding. Padahal yang 397B itu MoE lho, dengan 397 miliar parameter total.
Tim Qwen bilang mereka fokus ke stabilitas dan real-world utility. Feedback langsung dari komunitas yang ngebentuk model ini, bukan sekedar optimasi benchmark doang.
Ada dua varian weight yang tersedia di Hugging Face Hub: versi BF16 standar dan versi FP8 yang sudah di-quantize. Dua-duanya kompatibel dengan SGLang, vLLM, KTransformers, dan Hugging Face Transformers.
Fitur pertama yang wajib kamu tahu adalah Agentic Coding. Qwen3.6-27B dioptimasi khusus buat handle frontend workflows dan repository-level reasoning.
Artinya model ini paham cara kerja codebase besar, bisa navigasi struktur file, edit banyak file sekaligus, dan hasilnya konsisten serta runnable.
Di QwenWebBench, benchmark internal buat front-end code generation bilingual EN/CN, model ini skor 1487. Naik signifikan dari 1068 (Qwen3.5-27B) dan 1397 (Qwen3.6-35B-A3B).
Di NL2Repo yang tes repository-level code generation, skornya 36.2 versus 27.3 pendahulunya. Sementara di SWE-bench Verified, standar komunitas buat autonomous software engineering agents, Qwen3.6-27B mencapai 77.2.
Angka itu kompetitif banget sama Claude 4.5 Opus yang skor 80.9. Padahal Qwen ini open-weight dan bisa kamu jalankan sendiri.
Fitur kedua yang lebih arsitektural adalah Thinking Preservation. Biasanya LLM cuma nyimpan chain-of-thought reasoning buat pesan user saat ini. Reasoning dari turn sebelumnya? Dibuang.
Qwen3.6 punya opsi baru: preserve_thinking yang bisa diaktifin via API. Dengan ini, model nyimpan dan manfaatin thinking traces dari seluruh riwayat percakapan.
Buat iterative agent workflows, ini praktis banget. Model bawa forward context reasoning sebelumnya, gak perlu re-derive dari nol tiap turn. Hasilnya? Token consumption berkurang dan KV cache utilization meningkat.
Di balik layar, Qwen3.6-27B pakai arsitektur hybrid yang unik. 64 layer dengan pola berulang: 3 blok Gated DeltaNet → FFN, lalu 1 blok Gated Attention → FFN.
Tiga dari empat sublayer pakai Gated DeltaNet, bentuk linear attention. Cuma satu dari empat yang pakai self-attention standar. Kenapa?
Self-attention tradisional skalanya kuadratik O(n²) terhadap panjang sequence. Linear attention kayak DeltaNet skalanya linear O(n), jauh lebih cepat dan hemat memori buat konteks panjang.
Gated DeltaNet nambahin mekanisme gating yang belajar kapan update atau retain informasi. Mirip konsep LSTM tapi diaplikasiin ke attention computation.
Model ini juga pakai Multi-Token Prediction (MTP) yang enable speculative decoding. Generate beberapa kandidat token sekaligus, verifikasi paralel, throughput naik tanpa nurunin kualitas.
Context window native-nya 262.144 token, cukup buat codebase besar atau dokumen panjang. Kalau perlu lebih, bisa extend sampai 1.010.000 token pakai YaRN.
Tim Qwen saranin minimal 128K token context buat preserve thinking capabilities model.
Di SWE-bench Pro, Qwen3.6-27B skor 53.5 versus 51.2 (Qwen3.5-27B) dan 50.9 (Qwen3.5-397B-A17B). Model 27B ini ngalahin MoE 397B.
Terminal-Bench 2.0? 59.3, persis sama Claude 4.5 Opus. SkillsBench Avg5 naik drastis dari 27.2 jadi 48.2, improvement 77%.
Di reasoning benchmarks juga naik: GPQA Diamond 87.8, AIME26 94.1, LiveCodeBench v6 83.9. Vision-language benchmarks konsisten atau lebih baik dari pendahulu.
Praktisnya gini: kalau kamu developer yang butuh AI assistant buat coding kompleks, Qwen3.6-27B worth dicoba. Gratis, open-weight, Apache 2.0 license, dan performanya ngimbangi model proprietary mahal.
Aktifin preserve_thinking kalau pakai buat multi-turn conversations atau agent workflows. Efisiensi token-nya kerasa banget.
Versi FP8 recommended kalau hardware terbatas, performanya hampir identik dengan BF16. Setup-nya juga gampang dengan framework yang sudah support.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→

