Pelajari perbedaan CPU, GPU, TPU, NPU, dan LPU—lima arsitektur komputasi AI utama beserta kelebihan, kekurangan, dan use case masing-masing.
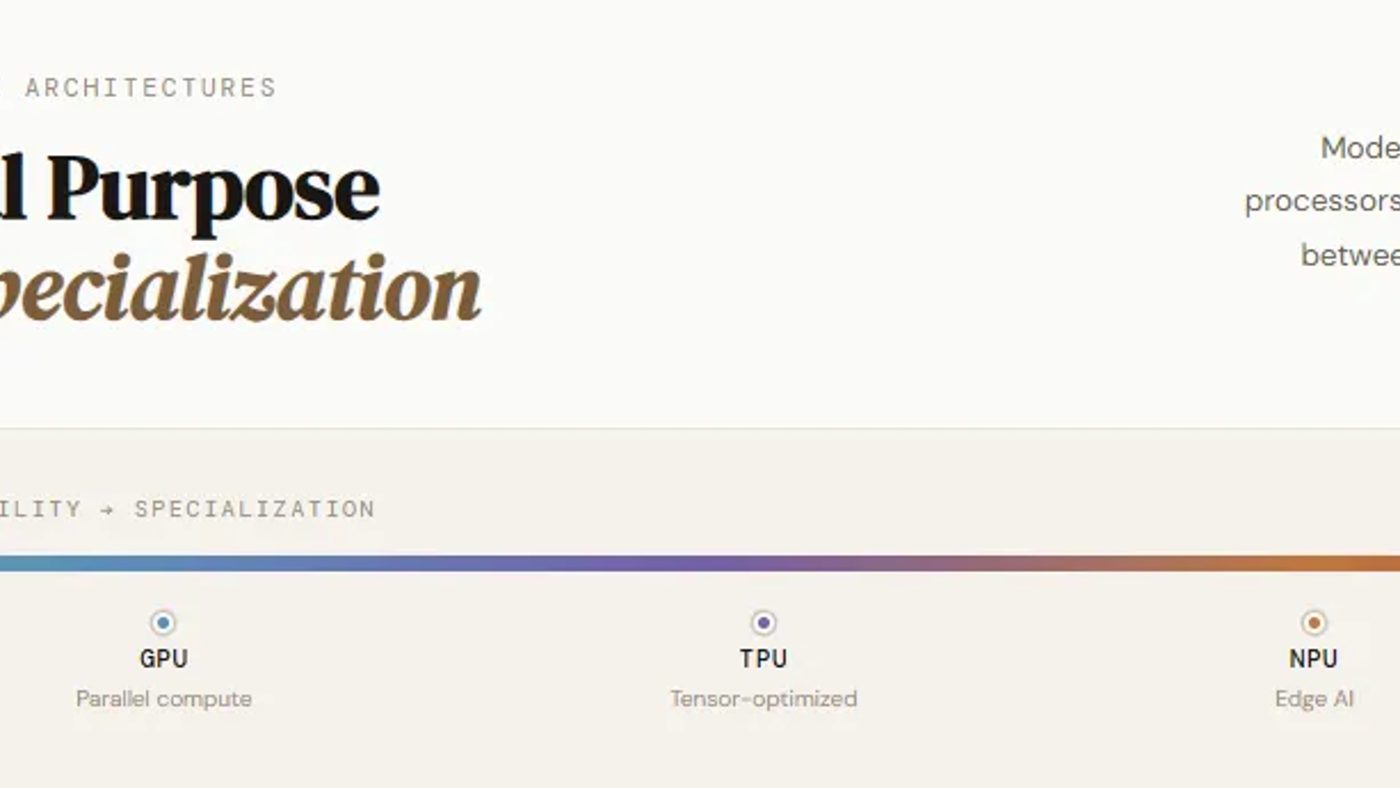
Dulu, komputer cuma pakai CPU untuk semua kerjaan. Tapi AI modern? Beda cerita. Sekarang ada berbagai jenis prosesor khusus, masing-masing dibuat untuk tugas tertentu.
Kalau kamu engineer AI, wajib paham perbedaannya. Nggak semua workload cocok dipaksa masuk ke GPU. Ada saatnya pakai CPU, TPU, bahkan LPU. Yuk, kita bahas satu per satu.
CPU: Otak Serbaguna
CPU itu seperti manajer handal. Dia bisa ngatur sistem, jalanin aplikasi, dan koordinasi hardware lain. Core-nya sedikit tapi powerful, cocok untuk tugas sequential.
Masalahnya, AI butuh paralelisme masif. Matrix multiplication yang jadi tulang punggung neural network? CPU kewalahan. Makanya CPU sekarang lebih sering jadi 'pengatur lalu lintas' sambil serahkan kerjaan berat ke accelerator.
GPU: Raja Training AI
GPU adalah pahlawan training model deep learning. Dulu buat grafis game, sekarang jadi mesin komputasi paralel berkat CUDA. Ribuan core kecil bekerja bareng, cocok banget untuk tensor operations.
Training model besar seperti GPT atau Stable Diffusion? Hampir pasti pakai GPU. Tapi harganya mahal, stok seret, dan butuh skill programming khusus. Untuk inference real-time, kadang overkill juga.
TPU: Spesialis Tensor dari Google
TPU dibuat Google khusus untuk neural network. Nggak fleksibel kayak GPU, tapi super efisien untuk tensor operations. Sistem search, rekomendasi, dan Gemini-nya Google? Semua jalan di TPU.
Arsitekturnya pakai systolic array—data mengalir seperti gelombang tanpa bolak-balik ke memory. Hasilnya? Speed dan efisiensi energi jauh di atas GPU untuk workload tertentu. Sayangnya, aksesnya terbatas ke Google Cloud dan ecosystem TensorFlow/JAX.
NPU: AI di Edge Device
NPU hadir untuk inference hemat daya di smartphone, laptop, dan IoT. Apple Neural Engine? Itu NPU. Intel juga punya versinya. Fokusnya: real-time AI dengan watt rendah.
Desainnya pakai MAC arrays dan on-chip SRAM, minim gerak data. Speech recognition, image processing, bahkan generative AI lokal bisa jalan tanpa cloud. Tradeoff-nya? Nggak bisa untuk training model besar atau tugas general-purpose.
LPU: Inference Super Cepat dari Groq
LPU adalah pendatang baru yang radical. Dibuat Groq khusus untuk inference LLM secepat kilat. Rahasianya? Hilangkan off-chip memory sama sekali—semua data di on-chip SRAM.
Hasilnya: latency super rendah, efisiensi energi 10x lebih baik dari GPU. Compiler yang kontrol eksekusi, bukan hardware scheduler. Tapi butuh ratusan chip untuk model besar karena memory per chip terbatas. Cocok untuk real-time applications yang butuh deterministik.
Mana yang Cocok untuk Kamu?
Pilih CPU untuk orchestrasi dan general computing. GPU masih king untuk training model besar. TPU efisien kalau kamu deep di ecosystem Google.
NPU pilih untuk edge AI dan user experience lokal. LPU pertimbangkan kalau latency adalah segalanya dan budget hardware masuk akal.
Takeaway Praktis
Jangan asal pakai GPU untuk semuanya. Pahami karakteristik workload-mu: butuh training atau inference? Parallel atau sequential? Edge atau data center?
Kombinasi heterogeneous—CPU ngatur, accelerator kerja—itu yang optimal. Mulai eksplorasi TPU untuk cost efficiency, NPU untuk produk consumer, dan pantau perkembangan LPU untuk next-gen inference.
AI Updates lagi bergerak cepat, jadi jangan cuma lihat headline.
MarkTechPost
Catatan redaksi
Kalau lo cuma ambil satu hal dari artikel ini
AI Updates update dari MarkTechPost.
Sumber asli
Artikel ini merupakan rewrite editorial dari laporan MarkTechPost.
Baca artikel asli di MarkTechPost→